#1052 closed enhancement (wontfix)
Tiger Geocoder 2010 Geocode() "squishing" toward end of block
| Reported by: | mikepease | Owned by: | robe |
|---|---|---|---|
| Priority: | medium | Milestone: | PostGIS Fund Me |
| Component: | tiger geocoder | Version: | master |
| Keywords: | Cc: | mikepease, woodbri |
Description ¶
I've been comparing the results of the Tiger Geocoder to Google's Geocoder. I sent in a list of about 70,000 addresses in Minnesota. I'm getting about 89% successful results where Google's geocode and Tiger's geocode produce similar results. Not bad.
One difference that I'd love to see in the Tiger Geocoder would be to place an address point either on the even or odd side of the street. It appears that the geocodes are all placed on the center line of the street. Is that correct?
It would be super cool if you could determine which side of the street an address is on and then shift the geocode to that side, say by 20 meters (65 feet). Now, determining which angle to translate the point can be a trick, for sure.
I did a similar operation in the past by grabbing a short line segment from the street and rotating it 90 degrees in order to find the even/odd side offsets from the center line. That code looked like this:
rotate_oncenter(
MakeLine(ST_Line_Interpolate_Point(ST_GeometryN(the_geom,1), offset_percent1 ), ST_Line_Interpolate_Point(ST_GeometryN(the_geom,1), offset_percent2 )) , 90) as rotated_line
… then you could use the end points of this rotated segment to get the even/odd odd side of the street. ST_Line_Interpolate_Point(rotated_line,0) —even side of street ST_Line_Interpolate_Point(rotated_line,1) —odd side of street
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (37)
comment:1 by , 14 years ago
| Component: | postgis → tiger geocoder |
|---|---|
| Owner: | changed from to |
comment:2 by , 14 years ago
Oops! Sorry, Paul! And thanks, robe (is that Rob?)
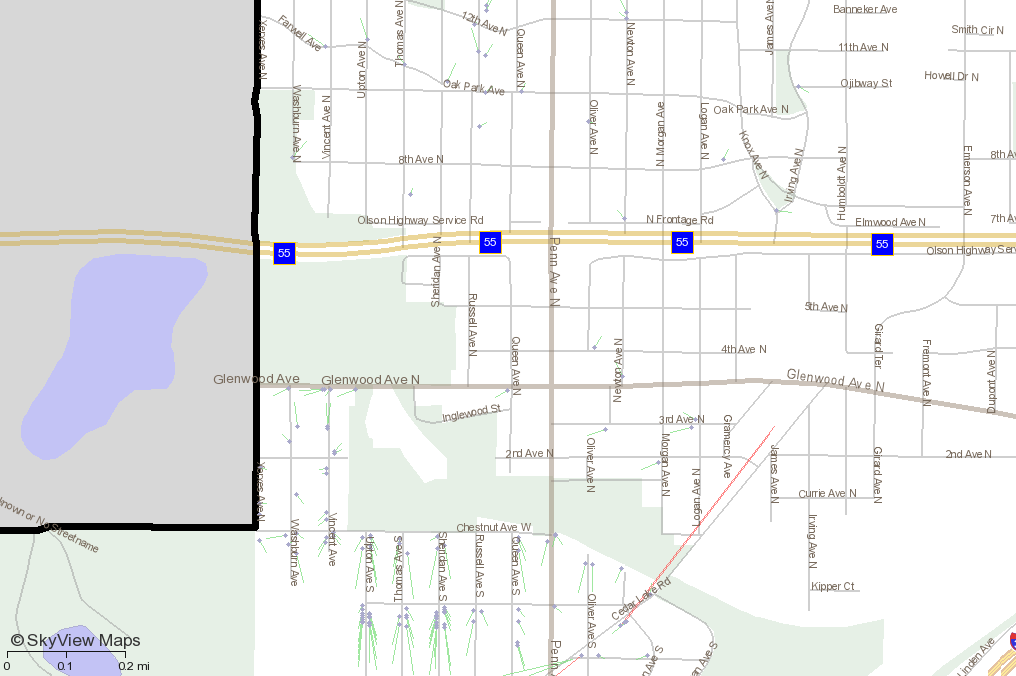
Here's a screen shot of how a bunch of points in the Minneapolis area are being placed in the center of the street rather than the the even/odd side. Also, note that the points seem to be shifted northward a bit as compared to where Google's geocoder places them. This is illustrated with a green line leading from the google point to the tiger point. Maybe that's a limitation of the tiger shapefiles?

comment:3 by , 14 years ago
Mike,
Thanks for the diagramatic map. This will be most helpful. I had noticed the same issue, but hadn't had the time to draw it out.
Regina Obe
comment:4 by , 14 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
| Version: | 1.5.X → trunk |
I set the offset at 10 meters in the interpolate point function.
Can you give it a try when you have the chance. For the samples I did, seemed to put it in the correct side of the street.
Haven investigated the shifting issue you brought up. I thought it might be because Tiger data is in WGS NAD 83 rather than Google's WGS 84, but haven't really noticed much of a difference between the 2 at least in areas I've tested.
by , 14 years ago
| Attachment: | shift_from_google_9-19-11.png added |
|---|
Points shiftted North compared to Google
comment:5 by , 14 years ago
| Resolution: | fixed |
|---|---|
| Status: | closed → reopened |
Hi, Regina.
I've tried your new version dated 9-01-11.
I'm attaching a new screenshot that shows the new geocodes are, in fact, offset to the even/odd sides of the street. Great! This was an important fix for my application because we often deal with boundary cases that go down a street, so we need to know which side of the street a location is.
However, there is still an issue with shifting North (or sometimes South) as compared to Google's geocoding. The green line in the image shows the relationship to where Google geocodes the points. Should I make this a separate issue so you can close out the even/odd issue?
comment:6 by , 14 years ago
Here's a list of addresses on a street in Minneapolis that illustrates this northward shifting. These addresses can be seen on the attached map dated 9-19-11 near 32nd Street and 32nd Ave.
Notice the higher the address number, the more northward shifting there is. Could this be an interpolation issue between 3200 and 3299? Maybe you're presuming the address could go up to 3299 when it really only goes up to let's say 3270 (for example).
Another note, these are South-side of downtown addresses (direction suffix). I noticed some Northeast suffix addresses had an opposite Southward shifting. A possible clue? Interpolation issue going the opposite direction?
Here's that list of addresses and the distance shifted from Google.
Meters From Google Address 22.834 3200 32nd Ave S Minneapolis MN 55406 31.251 3205 32nd Ave S Minneapolis MN 55406 31.824 3204 32nd Ave S Minneapolis MN 55406 34.182 3209 32nd Ave S Minneapolis MN 55406 34.530 3208 32nd Ave S Minneapolis MN 55406 38.692 3212 32nd Ave S Minneapolis MN 55406 42.118 3225 32nd Ave S Minneapolis MN 55406 43.093 3216 32nd Ave S Minneapolis MN 55406 46.284 3221 32nd Ave S Minneapolis MN 55406 46.568 3220 32nd Ave S Minneapolis MN 55406 54.371 3228 32nd Ave S Minneapolis MN 55406 54.371 3228 32nd Ave S Minneapolis MN 55406 54.371 3228 32nd Ave S Minneapolis MN 55406 58.716 3232 32nd Ave S Minneapolis MN 55406 63.291 3236 32nd Ave S Minneapolis MN 55406 67.121 3240 32nd Ave S Minneapolis MN 55406 71.185 3257 32nd Ave S Minneapolis MN 55406 71.834 3245 32nd Ave S Minneapolis MN 55406 72.053 3244 32nd Ave S Minneapolis MN 55406 74.568 3248 32nd Ave S Minneapolis MN 55406 74.568 3248 32nd Ave S Minneapolis MN 55406 75.418 3249 32nd Ave S Minneapolis MN 55406 78.707 3252 32nd Ave S Minneapolis MN 55406 80.377 3253 32nd Ave S Minneapolis MN 55406
comment:8 by , 14 years ago
Actually that would be better to make it a separate issue. Come to think of it, we do have the northward issue which I pushed to PostGIS Future. I'll push back to 2.0. #1147
by , 14 years ago
| Attachment: | north_south_shifting.png added |
|---|
"great divide" of north south shifting
comment:9 by , 14 years ago
I found some examples to illustrate how "Northside" addresses are shifted southward whereas southside addresses are shifted northward. You can see these examples in the 3rd attached image on Vincent Ave N/S. When this street switches from a north prefix to a south prefix, the shifting moves in the opposite direction.
Meters From Google Address 11.129 249 Vincent Ave N Minneapolis MN 55405 17.046 1124 Vincent Ave S Minneapolis MN 55405 22.022 280 Vincent Ave N Minneapolis MN 55405 25.775 211 Vincent Ave N Minneapolis MN 55405 27.298 1 Vincent Ave S Minneapolis MN 55405 27.908 284 Vincent Ave N Minneapolis MN 55405 29.190 217 Vincent Ave N Minneapolis MN 55405 29.772 9 Vincent Ave S Minneapolis MN 55405 43.322 20 Vincent Ave S Minneapolis MN 55405 61.427 323 Vincent Ave N Minneapolis MN 55405 66.088 319 Vincent Ave N #2 Minneapolis MN 55405
comment:10 by , 14 years ago
| Cc: | added |
|---|---|
| Summary: | Tiger Geocoder 2010 Geocode() to even/odd side of street → Tiger Geocoder 2010 Geocode() "squishing" toward end of block |
Hi, Regina.
I thought I'd check with you about this shifting of lat/lon as compared to Google's placement. Have you had a chance to investigate this issue?
Do you have an idea why the addresses are getting "squished" to the north (or south) end of a block?
comment:11 by , 14 years ago
Mike,
I investigated a little but haven't come to any conclusions yet. Mostly just haven't had enough breather time to concentrate for longer than 30 minutes at a time. So I think its just a matter of getting an hour or 2 of some quiet time to think thru the logic of what is going on here.
comment:12 by , 14 years ago
Mike,
I took another look at this. I did find a minor error with my interpolate, but that is not the cause of the issue here since it would only affect line segments with more than 2 points and many of these are 2 point line segments in tiger data.
Other cuase of distance issue is I think google's offset is higher than mine. I think I set it to 10 meters in the interpolate_from_address function. You can just change the default to higher. I'll probably change the default to higher later since I think 10 meters is too low.
The fundamental issue I think is precision of the raw tiger data versus google data. Just to clarify the process. The tiger data just has street ranges located in the addr table for LEFT and RIGTH side of streets. So in the simplest case, there are 2 records for each street segment — one for the right and one for the left. Lets take the 284 Vincent Ave N for example - I have a range of:
272 398 -- right side of street
So the logic interpolates between the 2 addresses to arrive at a fraction of: utm zone I get from utmzone function which for this area is 32615
-- 0.0952380952380952 and Point of
-- POINT(-93.3154622528598 44.9791255620491)
SELECT ST_Line_Locate_Point(ST_Transform(ST_GeomFromText('LINESTRING(-93.315971 44.978958,-93.315956 44.98074)',4269),32615), ST_Transform(ST_GeomFromText('POINT(-93.3154622528598 44.9791255620491)', 4326),32615));
-- note that answer is 0.0952380952380952381000
SELECT (284 - 272)*1.00/(398 - 272)*1.00
Google has:
POINT(-93.315596 44.979312)
Just in case the street is long, I convert to UTM zone first before interpolating the point then transform back to NAD 83 long lat.
To figure out what google thinks the fraction is I do this:
-- Answer: 0.199538688579411
SELECT ST_Line_Locate_Point(ST_Transform(ST_GeomFromText('LINESTRING(-93.315971 44.978958,-93.315956 44.98074)',4269),32615), ST_Transform(ST_GeomFromText('POINT(-93.315596 44.979312)', 4326),32615));
-- which using tiger range would put it at: 297
SELECT 272 + (398 - 272)*.19952
Now the question is: 1) Is google using street ranges or actual parcel data — it is not an estimation 2) Is Tiger range data for said issue streets in error. Tiger sometimes doesn't have the right ranges — perhaps data quality or as some have mentioned for privacy reasons.
I'm planning to put in some debugging logic in the interpolation and others so it spits out the street range etc. it's basing its guesses on — if debug is enabled using a global function that just returns true or false. This I'll use for the other functions as well, so I don't have to explicitly set it in each function.
comment:13 by , 14 years ago
Thanks for all the explanation.
I walked through the process of geocoding: 3253 32nd Ave S Minneapolis MN 55406
I found the row in the edges table for this street is gid=540165 The "rtoadd" column says 3299.
But in reality, I think the last address on that block is 3253. There are 13 houses on the block, and I think the address number goes up by 4 for each house.
So this discrepancy looks pretty consistent with the results I'm getting. Looking at the map I attached above to this bug report "shift_from_google_9-19-11.png", you can see the the south most address is getting shifted almost halfway up the block. Look at 32nd Ave between 32nd and 33rd street since almost every house is displayed on that block. All those addresses are squishing into the north half of the block.
That makes sense now if Tiger thinks the addresses should go all the way to 3299 but they really only go to 3253.
So, this unfortunately looks to be a pervasive problem in the street geometry here in Minnesota. Do you have any sense how prevalent this issue might be nationwide? And is there anything that could be done about it? I would imagine it's an enormous job to find the correct maximum address on each block in every state in the US.
Google seems to know what the correct max address is, however.
Would there be any way to compensate for an erroneous max address on a street segment?
Seems like a difficult issue to resolve.
comment:14 by , 14 years ago
I tried to manually change rtoadd and ltoadd in the tiger.edges and tiger_data.mn_edges tables to the correct max addresses of 3252 and 3253 for gid=540165 to see if the geocoder would get a better result, but the result ended up the same as before I changed those values.
Is there some other data I need to change for this to have an affect? A cache or index or something? I'm confused that it didn't change the result.
comment:15 by , 14 years ago
Mike,
Wrong table. The PostGIS tiger geocoders uses the mn_addr (for street number ranges) since that is more accurate. In theory they should be the same but for many roads like some really complex ones they aren't and in fact addr might have more than 2 records per tlid.
So update the corresponding records in mn_addr where the tlid is the same as your mn_edges table corresponding to your gid.
comment:16 by , 14 years ago
BINGO!
I found tlid = 43639801 and gid = 330411 and gid = 368926 in the tiger.mn_addr table.
I changed the "tohn" fields to be 3252 and 3253 for the max address on that block..
Then I tried:
select st_x(geomout), st_y(geomout), * from geocode('3253 32nd Ave S Minneapolis MN 55406')
That moved the latitude south as expected to the end of the block where it belongs. To be precise, it moved it slightly too far south, I think for two reasons.
1) The geometry for that street line segment actually goes a little farther south than the more precise MN-DOT street file I have and farther south than Google's street data too. The difference here is maybe about 5 to 10 meters.
2) Also, I think maybe your interpolation might put the point at the very edge of the block rather than have a bit of a "margin" from the end. I would think the top and bottom edges should be offset 10-20 meters from the end of the line segment because a house wouldn't likely be on the very edge of the segment. I think the end of the segment is at the center line of the cross street, so you'd need to compensate a margin to get the point off of the street and centered a bit on that last parcel on the street.
Anyway, that's seems to be the more minor issue here. The big issue appears to be that the Tiger data commonly has the incorrect "tohn" (max address number) for its address tables.
That could be an icky problem. What are your thoughts?
comment:17 by , 14 years ago
If it's intentional as some may have suggested then not much can be done about that. If it's just in error then would be interesting to see if we can come up with some way of contributing corrections back. Not sure if OpenStreetMap (OSM) does that already. I also haven't compared to see how the accuracy between OSM and the Tiger 2010 compares. I suspect OSM may be more accurate in some areas since the data is being constantly updated and I know several local Govs also contribute edits to OSM directly, but they also originally pulled some data from tiger and I'm not sure the vintage of the pull if they have all the 2010 corrections.
anyway I am interested in making a plpgsql only geocoder patterned after the tiger one based on OSM data if there is demand for it. That would then cover more of the world, but yet be hopefully simple to install and use in spatial queries with no dependency except for PostGIS and the data.
comment:18 by , 14 years ago
the shifting you are seeing is fundemental to the way the TIGER data is laid out. Each block has a *max* street address, by design. When addresses on a block are recorded, they use some part of the range, with left overs for later..
comment:19 by , 14 years ago
Hmm. So, if I understand this correctly, the "tohn" doesn't have the same meaning as it's being used for by the geocoder.
I think the geocoder assumes the "tohn" is the highest address number that actually EXISTS. But I think you're saying that the real definition of this column is that "tohn" is the highest POSSIBLE address number, not necessarily one that exists.
Am I understanding that correctly? If so, that seems like a fundamental limitation to the precision of the Tiger geocoder. You get a house to the correct block, but its location within that block can't be precisely figured unless somehow the highest EXISTING house number is known. And when the highest existing number is lower than the highest possible number, it will follow this "squishing" pattern that we've been seeing.
I suspect my client won't be satisfied with that level of precision. Do you know if this is prevalent throughout all the Tiger address data?
I wonder if there is any clever solution to this.
You could "cheat" if this condition is known to be true most/all of the time. For example, if tohn=3299 but you're pretty sure the real max is 3250, then the offset from the end of the block could be roughly doubled.
3250 is at the 50% mark of the address range, but really at the far end of the block. If the full block was 1000m and the geocoder originally says the 3250 house is 500m from the start, you could scale that offset up to 1000m.
I guess the trick here is still knowing the actual highest address number. What if an assumption was made that the "tohn" is generally higher than the real highest number? Could scaling the offset produce *better* (even if not correct) results?
Did any of that make sense?
![]()
comment:20 by , 14 years ago
For the Open Street Map geocoder, are you referring to Nominatim? I tried this query:
Interestingly, the lat/lon result for 3253 32nd Ave S looks like it has the same result that your Tiger geocoder does. It places the point in the middle of the block instead of the end of the block.
Out of curiousity, I tried Yahoo Maps. Wouldn't you know it? Yahoo also incorrectly puts the address in the middle of the block.
Then, I tried MapQuest. Same wrong answer in the middle of the block.
So, then I tried BING Maps. That got the right answer, like Google at the end of the block.
I don't know what that tells you, but it's at least interesting to know that your geocoder isn't the only one behaving this way. I wonder if Yahoo & Mapquest have this "squishing" effect as often as I'm seeing it with the Tiger geocoder.
comment:21 by , 14 years ago
If Brian's (dbb) comment is right that Tiger always does this then Mike your solution would work. Brian, how sure are you about this. I haven't been paying attention myself.
We could at least get less squishing if we assume it's the case and then cut as a function of ratio of range to length of street or something like that except when the user does ask for an address that is at the end.
At any rate I think your other idea of shortening the string length we consider so addresses at the end don't flush at the end of the street is a good idea.
As far as comparison's. I think MapQuest is based on nominatum so the fact they produce similar answers is no surprise. I suspect both Google and Bing are using more than interpolation and they are considering real addresses in there calculations, so their data is just better - presumably navteq based.
Yes nominatim is what I was thinking about but didn't like it because it seems to have too many web servicey gooey dependencies and for my needs — which is mostly datawarehouse stuff, I Ideally need everything to run in the database and be self-contained (not so many moving parts) like needing a web server component.
comment:22 by , 14 years ago
| Cc: | added |
|---|
Hi All, I'm somewhat late to this thread but I can add a little to this. Tiger tends to round ranges up to 99-100 unless it overlaps with another range on an adjacent street, and it might do the rounding anyway because Census mandate to not uniquely identify any single response. This means you will get a general shift of address locations to the beginning of the segment as digitized. This probably accounts for the the north-south shifts you were seeing above.
OSM imported all of Tiger in 2006 before the first Tiger shape files were released if I'm not mistaken. So all the test on 3253 32nd Ave S that ended in the middle of the street are probably based on Tiger data. Bing addresses are "Rooftop, Address" so they probably have parcel data that is augmented with road range data for rural areas. Google has acquired parcel data and they also collect street numbers as part of they street view data collection.
Tiger data is just broken! That said it is still great data for the cost, coverage, etc, but you have to understand these limitations.
There was some discussion on another list (but I can not find it now) about trying to analyze the Tiger segments by looking at adjacent segment ranges to see if it was possible to modify the value in a reasonable way. At the same time it might be possible to populate street names on no name segments based on such an analysis. But this is getting into a whole other discussion and there are problems like how to you reapply this as subsequent Tiger releases come out.
comment:23 by , 14 years ago
Steve,
Thanks for the great input. That answered a lot of questions. I can't help but think if there were some way to provide back corrections to Tiger in a painless way for everybody. So that Tiger becomes better. That's part of what my thinking was with maintaining the tiger tlids for the topology loader.
It may be broken, but everything is in some way and as long as you understand where the breaks are that is all I think one can hope for. Like you said its a good source given the price and I'm impressed with the improvements they have made. Besides I don't have the space to store all parcel data in the country so interpolation in many cases is good enough given the savings space.
comment:24 by , 14 years ago
[a somewhat off topic response]
Making Tiger better is somewhat problematic because you would want a process that feeds back into Census, but they have restrictions on what they are allowed to have. But I assume some stuff could go back to them. I thought about building a crowd sourced site to improve tiger and I think you can pretty easily build a "changes" database that would allow you to apply changes to incoming Tiger data but only if Census has not modified it. You would build a table structure something like:
file_or_table_name | uid | field_name | old_value | new_value | userid | timestamp
Then you only apply changes if the old value matches the Tiger data and you can report if something has changed and needs to be reviewed. And you have the obvious issues of multiple people entering conflict input, etc.
It would be great if there was an open collection of parcel data, but even if you could collect it at the county level means you have to deal with about 3300 counties and convince them to open up that data. If you had to go to every town and municipality it would take forever. Since this data is in theory open public record data via the tax roles, it should be do able if you could get enough volunteers.
comment:25 by , 14 years ago
A couple thoughts I might add. TIGER does in fact store "theoretical" address ranges, typically by 100s I believe, and it gets even more fun when they have a range, for example 9100-9198, then if someone actually lives at 9100, they'll store another value there for the supposed privacy protection of the person living at 9100. I believe it's due to something called "Title 13" somewhere in federal statutes.
One thing I'm not sure if this has contributed to some of the reported errors, but there is no guarantee in TIGER that fromhn < tohn. The from and the to correspond simply to the drawing order of the points in the street edge geometry, so that if the points were entered in opposition to address flow order, then fromhn will be > tohn. They are usually consistent between the assignment of the 'L' or 'R' in the side of street in the addr table and the edge geometry. But I believe there would then be cases in the line interpolation that if the initial % comes out as 60, you would want to convert that to 40.
Then, as far as dealing with the 'squishing' effect because of true vs. theoretical address ranging, there will occasionally be addressing jurisdictions where true and theoretical coincide pretty well. For example, in Boulder CO I noticed that house numbers jump by more than two as you go up the street, so the theoretical address range will be more completely used. Here in the Austin TX area, house numbers jump by 2.
I've never come up with a good idea how to overcome the squishing if you do not have some clear idea what the max true address on a segment is. Perhaps some kind of statistical thing that builds over time for an area that observes that addrs are likely being squished? That wouldn't be very reliable.
I do believe google makes heavy use of actual parcels with stored true addresses. You sure see them displayed often, and my own address appeared smack in the middle of my displayed parcel.
I never considered the interpolation error of failing to assume the house is not right on the lot line for the lowest and highest addresses on a segment (i.e., not nudging them inward). The squishing effect is so extreme, it never occurred to me
comment:26 by , 13 years ago
| Milestone: | PostGIS 2.0.0 → PostGIS 2.1.0 |
|---|
comment:27 by , 12 years ago
Hi, Regina. Long time no talk- I had a couple thoughts on this "squishing" recently.
1) Parcel data is becoming more available. Minnesota now offers free access to the Twin Cities metro parcel data with geometry for all properties. The tiger geocoder potentially could look for parcel data when available for a given area.
Or another approach is to clean up the Tiger address ranges.
2) Cross-reference the to/from address ranges for each street with the US Postal Office database. There is a service I've experimented with that provides a web-based interface to the USPS address database. It is: http://smartystreets.com
It's fast and cheap. For non-profits, I think there is a free option. You send it a list of addresses and it sends back the list with post office codes appended that signify things like if it's a real address.
I could imagine writing some code to automate this cross referencing the millions of street segments in the Tiger database. The result could be to find out the REAL min and max address ranges for every block.
Also, I've spoken to the management of this small business about a month ago. They were in the process of enchancing their limited geocoding capability. They geocoded down to a zip+4 level, not to the street. Perhaps there is a potential for a partnership between you and them?
comment:28 by , 12 years ago
Mike,
I think that Tiger has closer to 30-40 million records and you have the problem of doing this every year that they release data updates. I have I thought about a way to create extra tables to store this information in and then reapply it if appropriate to successive updates.
It would also be possible to license the USPS zip+4 data and match that to the Tiger data to improve the data. At some point you need to ask if licensing something like Navteq isn't a more appropriate if you can afford that.
Speaking of parcels, I just added them to my Navteq geocoder (not based on the this Tiger geocoder) but the process was reasonably trivial since the parcel points were linked to the street segments. If you use straight parcel data then you have to build and standardize the addresses of the parcels and query them separately, or preprocess the data to link them to the appropriate Tiger edges.
Anyway, I would be interested in working on either of these projects also.
comment:29 by , 12 years ago
Hi all,
Regarding parcel data. I agree a lot of states have it e.g. MA has pretty much full set for the whole state and I use just the Boston piece which I get directly from Boston Assessing source so is more detailed. But I think as Steve alluded to, the structure is not consistently kept across all states unless you go with a single source like Navteq that has already standardized it for you and then for my purposes I care about parcel data a lot so I have it more integrated in my workflow than any geocoder can and I suspect it might be the case with others wanting that level of geocoding. That they wouldn't want to keep two sets when they've got a super detailed one handy already.
On another note, while all these considerations are important, I don't want to lose site of my primary goal. That is not to be the very best geocoder (or even compete with Google et. al) but basically creating a lightish-weight geocoder that is good-enough for general use and easy enough to install for any PostGIS installation.
Piling on more data, while making the geocoder more accurate I think will move it further away from grasp of your general user since it would require more disk space, more prepping etc.
So priority wise, I want to focus on improving the normalization routines — that to me is the biggest bang for the general user right now (it will mean better accuracy and speed (you won't be having those 1 minute calls in the every 100 30 ms calls) and that already is a bagfull) — which I've been working with Steve to see if I can integrate his PAGC normalizer. So that's where I am with all this.
comment:30 by , 12 years ago
I think I am aligned with keeping the postgis tiger geocoder a simple, easy to install tool that can be used by a wide audience with minimal fussing around. <shameless plug> That said, if anyone needs any custom work or additional data integration, I do this all the time and have been creating custom geocoding solutions for the last 12 years so send me an email woodbri (at) swoodbridge (dot) com.
comment:32 by , 12 years ago
| Milestone: | PostGIS 2.1.0 → PostGIS Future |
|---|
comment:33 by , 12 years ago
I think that this could be closed as will not fix or not a bug. This is a Census data problem/limitation not a geocoder problem.
If someone want to open an enhancement request to support parcel data, then I think that would be appropriate and maybe we could look at applying the PAGC address standardizer to that task after it is integrated into tiger geocoder.
Well it's supposed to be returning on either even or odd. That's the point of the faces check I think. But perhaps you have found the bug I've been too lazy to investigate that it's not putting it in the correct side of the street.
Mike,
for future tiger geocoder bug tickets — we do have a component option now called "tiger geocoder". Please specify that one. Poor Paul is already overworked, and when you take the default "postgis" — it gets dumped on his shoulders.