| Version 22 (modified by , 15 years ago) ( diff ) |
|---|
PostGIS WKT Raster Tutorial 1 - Intersecting vector buffers with large raster coverage using PostGIS WKT Raster ¶
Pierre Racine, June 2010
This tutorial will show you how to do a very classical raster/vector analysis with PostGIS WKT Raster. Basically the problem is to compute the mean elevation for buffers surrounding a series of point representing caribou observations. You can do this kind of analysis pretty easily in any GIS package but what is special here and is not easy to do in ANY GIS package is the size of the datasets used (900 MB or raster data), the simplicity of the queries and the speed at which we will get the results.
We will describe the steps mainly on Windows, but Linux gurus will have no problem writing the equivalent commands in their favorite OS. We assume that PostgreSQL, PostGIS and PostGIS WKT Raster are well installed. Refer to the readme file of each software to install them properly. The version used are:
- PostgreSQL 8.4
- PostGIS 1.5.1
- WKT Raster: We compiled the last code available.
- GDAL 1.6: You will have to compile it before WKT Raster.
- Python 2.6 or 2.5
- GDAL 1.6 binaries for GDAL for Python
- GDAL 1.6 for Python 2.6 (or GDAL 1.6 for Python 2.5)
- Numpy 1.4 for Python 2.6
- OpenJUMP 1.3
We will use two different datasets:
- The first dataset is a point shapefile of 814 caribou observations done by airplane in the northern part of the province of Quebec by the provincial ministry of natural ressources between 1999 and 2005. We will see later in the tutorial how you can easily produce a similar point cover.
- The second dataset is a series of 13 SRTM elevation rasters covering most of the province of Quebec. These free rasters, available on the web, are 6000x6000 pixels each, have a pixel size of about 60 x 90 meters and weight a total of 900 MB once unzipped. There are many versions of SRTM. We choose the one at ftp://srtm.csi.cgiar.org/. You can find a pretty good description of this dataset in Wikipedia (http://en.wikipedia.org/wiki/SRTM).
We will import the shapefile and the raster coverage into PostGIS, create buffers around each point and then intersect those buffers with the elevation coverage in order to get a weighted mean elevation for each buffer. We will have a graphical look at the different results along the way using OpenJUMP.
Loading the caribou points shapefile into PostGIS ¶
This operation is very straightforward for any casual PostGIS user. There are many ways to import a shapefile into PostGIS. You can use the classical loader provided with PostGIS (shp2pgsql.exe) or the GUI one integrated into pgAdmin III. You can also use GDAL/OGR, OpenJUMP or QGIS. The classical PostGIS loader and GDAL/ORG are command line programs and PostGIS GUI, OpenJUMP and QGIS are graphical user interfaces (GUI). PostGIS WKT Raster does not have a GUI loader yet. It comes with a Python command line loader (gdal2wktraster.py, thanks to Mateusz Loskot) very similar to PostGIS shp2pgsql.exe. We will import both datasets using those loaders in order to appreciate the similitudes.
Here is the procedure to import the caribou point shapefile:
Launch a command prompt (or a shell under Linux) and make sure you can execute "shp2pgsql". If this works, you should get the help for the shp2pgsql command. If not, make sure the folder where it is located ("PostgreSQL_Installation_Path/bin") is in you PATH environment variable or simply type the complete path to shp2pgsql like this:
>"C:/Program Files/PostgreSQL/8.4/bin/shp2pgsql"
shp2pgsql works in two steps: The first step is to create a .sql file that you then have to execute using "psql", an application included with PostgreSQL. To convert the caribou point shapefile in "cariboupoint.sql", we do the following:
>"C:/Program Files/PostgreSQL/8.4/bin/shp2pgsql" -s 32198 -I C:\Temp\TutData\cariboupoints.shp > C:\Temp\TutData\cariboupoints.sql
The -s option tells the loader that the shapefile points are stored in the Quebec Lambert spatial reference system which has SRID number 32198 in the PostGIS spatial_ref_sys table.
The -I tell the loader to add a line to create a spatial index on the table.
The resulting sql commands are copied to the .sql file using the ">" pipe command.
Assuming you have already created a database when you installed PostGIS and that you named it "tutorial01", you can then execute the sql file with "psql" like this:
>"C:/Program Files/PostgreSQL/8.4/bin/psql" -f C:\Temp\TutData\cariboupoints.sql tutorial01
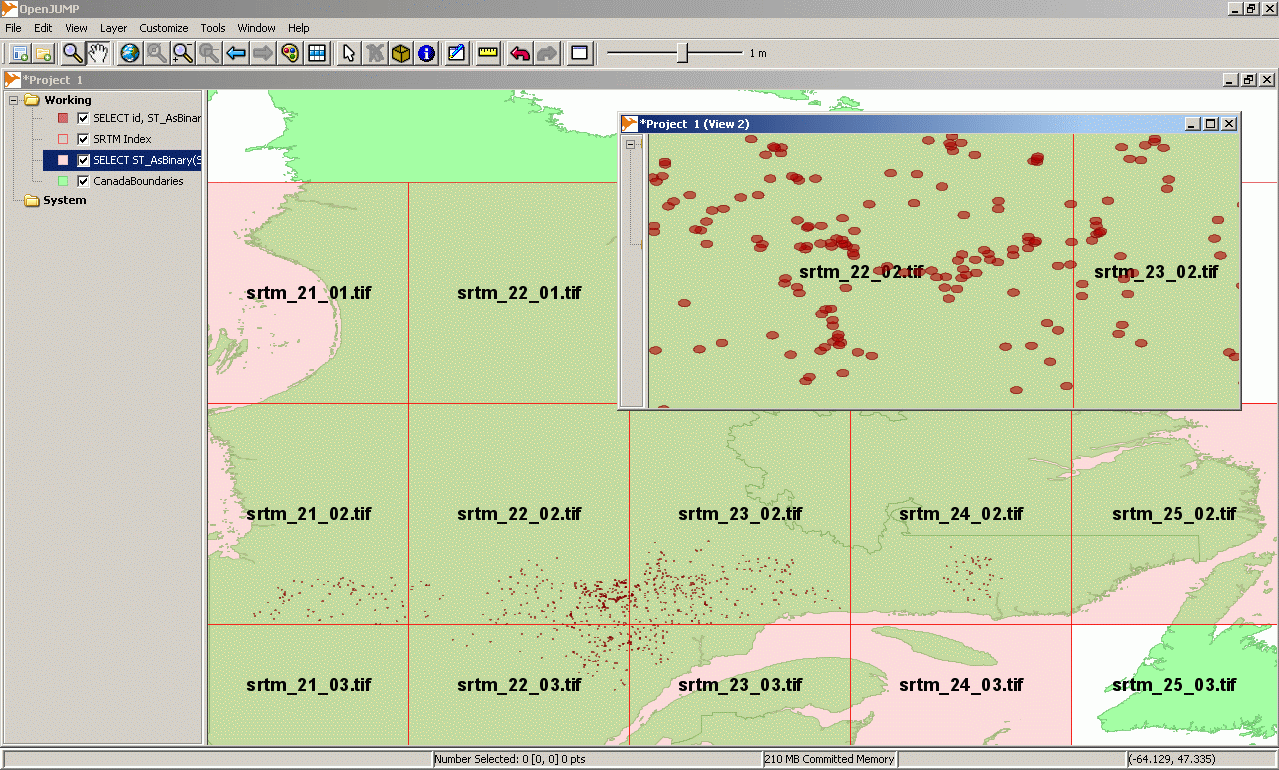
Visualizing the caribou point in OpenJUMP ¶
The favorite tool of the PostGIS community to display geometries loaded into PostGIS is OpenJUMP. This java open source software is very easy to install and work very well with PostGIS. Once OpenJUMP have been installed, you can view the caribou points by following these steps:
- Start OpenJUMP and select "Layer→Run Datastore Query" from the menu.
- Create a connection to PostGIS by clicking the icon on the right of the connection field and adding a new connection with the "name" of your choice, the "localhost" server at port "5432", on your database instance (here "tutorial01") with your PostgreSQL "username" and "password". Click OK to establish the connection to PostGIS.
- In the query field, type the following command:
SELECT id, ST_AsBinary(the_geom)
FROM cariboupoints;
You should see your caribou observation points appear in the OpenJUMP map window.
Loading the SRTM elevation rasters into PostGIS WKT Raster ¶
The process to load the elevation raster data is very similar. The name of the loader is gdal2wktraster.py. It is a Python program dependent on the Python package and the GDAL Python package. It is located in the same folder as shp2pgsql. You can call it directly or with its full path if you did not change your PATH environment variable.
To display gdal2wktraster.py help, simply do:
>"C:/Program Files/PostgreSQL/8.4/bin/gdal2wktraster.py" -h
We downloaded 8 zipped files. If you have 7-Zip installed, you can simply select all the zip files, right-click on them and select "7-Zip→Extract files…" 7-Zip will extract each TIF file in the same folder. You can then create another folder and move them there. Each file is 6000 pixels wide by 6000 pixel high. You can quickly preview the images if you have IrfanView installed. Efficient raster/vector analysis with PostGIS WKT Raster requires the raster files to be split into tiles in the database. Fortunately gdal2wktraster.py has an option to tile the images the size we like. We will tile them into 100x100 pixels resulting in 60 * 60 * 13 = 46800 tiles. gdal2wktraster.py also accepts wildcard so we will be able to load our 8 big raster in one sole command.
To load the raster files in PostGIS WKT Raster, do something like:
>"C:/Program Files/PostgreSQL/8.4/bin/gdal2wktraster.py" -r C:\Temp\TutData\SRTM\tif\*.tif -t srtm_tiled -s 4326 -k 100x100 -I > C:\Temp\TutData\SRTM\srtm.sql
The -r option indicate the series of raster we want to load in the database.
The -t option specify the table in which we want to load them.
Similar to shp2pgsql.exe, the -s option is required to specify the spatial reference system ID. In this case the raster are in "WGS 84" having the SRID number 4326. Unlike some GIS software, PostGIS does not support on the fly reprojection so that we cannot do operations on table stored in different spatial reference systems. As we could see, the caribou point layer was in the projected spatial reference system NAD 83/Quebec Lambert", when the SRTM images are in the geographic spatial reference system "WGS 84". We will have to deal with this later.
The last -k option specify the size of the tiles we want to load in PostGIS.
The -I option tells the loader to create a spatial index on the raster tile table. If you forget to add this option you can always add the index by executing a SQL command similar to this one:
CREATE INDEX srtm_tiled_gist_idx ON srtm_tiled USING GIST (ST_ConvexHull(rast));
The result of the gdal2wktraster.py command is a 1.8 GB .sql file produced in 1 minute on my brand new Lenovo X201 labtop (Intel Core i5, 1.17 GHz, 3 GB or RAM ![]() .
.
The same way we loaded the caribou point sql command file, we will load this sql file using "psql":
>psql -f C:\Temp\TutData\SRTM\srtm.sql tutorial01
This process took less than 4 minutes. You can quickly verify the success of the loading operation by looking at the number of row present in the "srtm_tiled" table. There should be 46800 rows.
You can then visualize the extent of each of those 46800 rasters by typing the following command in the OpenJUMP "Run Datastore Query" dialog:
SELECT rid, ST_AsBinary(rast::geometry) FROM srtm_tiled;
You can also view the complete area covered by the raster coverage as one geometry by doing this:
SELECT ST_AsBinary(ST_Buffer(ST_Union(rast::geometry), 0.000001)) FROM srtm_tiled;
As you can see, unlike most raster coverage loaded into a GIS, the area covered by this single table raster coverage is not strictly rectangular and the two big missing square areas are not filled with nodata values. Here you have only one table for the whole coverage which is build from many raster files loaded in a single step. You don't need 13 tables to store 13 rasters. We did this with one band SRTM files in TIF format, but it could have been 3 bands BMP files of JPEG and the total size of the coverage does not really matter (PostgreSQL has a limit of 32 Terabytes)…
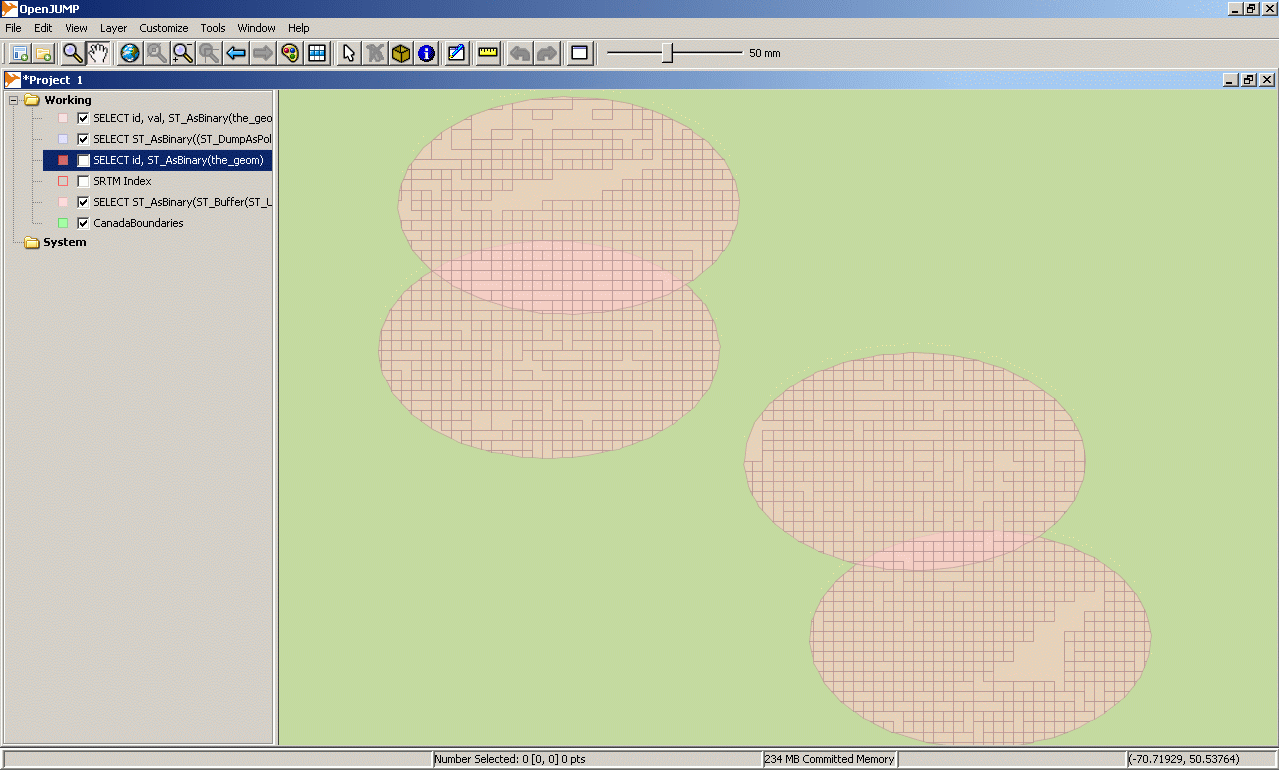
If you want to go to the pixel level and verify the integrity of the values associated to a sample of the raster, (thanks to Jorge Arevalo and GDAL) you can view a vectorization of one of the tile (vectorizing all the table would be way too long) in OpenJUMP. Just type the following SQL query in the same query dialog:
SELECT ST_AsBinary((ST_DumpAsPolygons(rast)).geom), (ST_DumpAsPolygons(rast)).val
FROM srtm_tiled
WHERE rid=34;
You will notice that a small area in the upper left corner of the tile is missing. This is the nodata value area. Any analysis function in PostGIS WKT Raster takes the nodata value into account. That means those area will be omitted from the operation. For example in the upcoming intersection operation, if one buffer falls in a nodata value area, st_intersection() and st_intersects() will ignore any part of the raster with nodata values possibly resulting in no intersection at all.
You can verify that your raster has a nodatavalues set and the effective value of the nodata value by doing this query:
SELECT ST_BandHasNodataValue(rast), ST_BandNodataValue(rast)
FROM srtm_tiled
LIMIT 1;
I you want a query to ignore the nodata value set and treat it like any other value, you can always replace any rast argument with ST_SetBandHasNodataValue(rast, FALSE) like in this query:
SELECT ST_AsBinary((ST_DumpAsPolygons(ST_SetBandHasNodataValue(rast, FALSE))).geom),
(ST_DumpAsPolygons(ST_SetBandHasNodataValue(rast, FALSE))).val
FROM srtm_tiled
WHERE rid=34;
Producing a random point table similar to the caribou shapefile ¶
Now that we know the extent of our elevation data, we can produce a table similar to the caribou_point one. For this we will use a function that generate a certain number of point geometry inside a polygon. Copy this function in the pgAdmin III query window and execute it:
CREATE OR REPLACE FUNCTION ST_RandomPoints(geom geometry, nb int)
RETURNS SETOF geometry AS
$$
DECLARE
pt geometry;
xmin float8;
xmax float8;
ymin float8;
ymax float8;
xrange float8;
yrange float8;
srid int;
count integer := 0;
bcontains boolean := FALSE;
gtype text;
BEGIN
SELECT ST_GeometryType(geom)
INTO gtype;
IF ( gtype != 'ST_Polygon' ) AND ( gtype != 'ST_MultiPolygon' ) THEN
RAISE EXCEPTION 'Attempting to get random point in a non polygon geometry';
END IF;
SELECT ST_XMin(geom), ST_XMax(geom), ST_YMin(geom), ST_YMax(geom), ST_SRID(geom)
INTO xmin, xmax, ymin, ymax, srid;
SELECT xmax - xmin, ymax - ymin
INTO xrange, yrange;
WHILE count < nb LOOP
SELECT ST_SetSRID(ST_MakePoint(xmin + xrange * random(), ymin + yrange * random()), srid)
INTO pt;
SELECT ST_Contains(geom, pt)
INTO bcontains;
IF bcontains THEN
count := count + 1;
RETURN NEXT pt;
END IF;
END LOOP;
RETURN;
END;
$$
LANGUAGE 'plpgsql' IMMUTABLE STRICT;
You can then generate a fake cariboupoints table with 814 points doing this query:
CREATE TABLE cariboupoints AS
SELECT generate_series(1,1000) id,
ST_RandomPoint(the_geom, 1000) the_geom
FROM (SELECT ST_Transform(ST_Extent(rast::geometry), 32198)
FROM srtm_tiled
) foo;
Similarly you can visualise your own caribou point layer with this OpenJUMP query:
SELECT id, ST_AsBinary(the_geom)
FROM cariboupoints;
Now that we have our two coverages loaded in the database and that we are confident about their values and spatial reference, let's start doing some analysis queries…
Making buffers around the caribou points ¶
This operation is also very straightforward for any casual PostGIS user. The caribou point table is in a spatial reference system suitable for measurements in meters so we can build our buffers in this system and then convert them to the raster one later in order to intersects them. We will make 1 km buffers around our points and save them as a new table. We do this operation in a pgAdmin III query window (not in OpenJUMP):
CREATE TABLE cariboupoint_buffers AS
SELECT id, ST_Buffer(the_geom, 1000) the_geom
FROM cariboupoints;
Again you can display your buffers in OpenJUMP with this query:
SELECT id, ST_AsBinary(the_geom)
FROM cariboupoint_buffers;
We then reproject our buffers to WGS 84 so we can intersect them with our raster coverage:
CREATE TABLE cariboupoint_buffers_wgs AS
SELECT id, ST_Transform(the_geom, 4326) the_geom
FROM cariboupoint_buffers;
Again the same kind of query to display them in OpenJUMP and confirm that they overlap with the raster coverage and see that now they are a bit squashed:
SELECT id, ST_AsBinary(the_geom)
FROM cariboupoint_buffers_wgs;
We could have done those two queries in one:
CREATE TABLE cariboupoint_buffers_wgs AS
SELECT id, ST_Transform(ST_Buffer(the_geom, 1000), 4326) the_geom
FROM cariboupoints;
We then create a spatial index on this last table to make sure the next intersection operation will be done as quickly as possible:
CREATE INDEX cariboupoint_buffers_wgs_geom_idx ON cariboupoint_buffers_wgs USING GIST (the_geom);
Intersecting the caribou buffers with the elevation rasters ¶
Our two coverages are now ready to be intersected. We will use the brand new st_intersection() function and st_intersects() operator which operates directly on raster and geometries by vectorizing only the necessary part of the raster before doing the intersection and is one of the main feature of PostGIS WKT Raster:
CREATE TABLE caribou_srtm_inter AS
SELECT id,
(st_intersection(rast, the_geom)).geom the_geom,
(st_intersection(rast, the_geom)).val
FROM cariboupoint_buffers_wgs,
srtm_tiled
WHERE st_intersects(rast, the_geom);
This query takes about 30 minutes to complete. It can greatly be optimized by invoquing the st_intersection only once with the help of a subquery producing record values that we split later in the main query like this:
CREATE TABLE caribou_srtm_inter AS
SELECT id,
(gv).geom the_geom,
(gv).val
FROM (SELECT id,
st_intersection(rast, the_geom) gv
FROM srtm_tiled,
cariboupoint_buffers_wgs
WHERE st_intersects(rast, the_geom)
) foo;
This version takes only 17 minutes. Almost half the time spent by the preceding one… This little increase in complexity certainly worths the gain in performance.
Once again you can visualise the result of the query by doing this query in OpenJUMP (you might have to increase RAM allowed to OpenJUMP by changing "-Xmx256M" to "-Xmx1024M" in "OpenJUMPInstallPath/bin/openjump.bat"):
SELECT id, val, ST_AsBinary(the_geom)
FROM caribou_srtm_inter;
One approach to make this operation without PostGIS WKT Raster would have been to first convert our 13 rasters to 13 shapefiles, import them in PostGIS and do a traditional intersection query between geometries only. The problem is that converting only one of those SRTM file is very difficult… The vector version of only one of those files exceed the limit of 2 GB imposed on shapefiles and the GML equivalent file is more than 10 GB… The WKT Raster approach goes like this: "since it is mostly impossible to convert those raster to vector, load them all into PostGIS as is and only the smallest part of them raster will be vectorized to do the requested operation", this using the very efficient GiST index, the versatility of GDAL and of power of the postGIS vector engine.
Summarizing the elevation values for each buffer ¶
The last step of our analysis is to summarize the elevation for each buffer by computing 814 weighted mean elevations. "Weighted mean elevation" means that if the area occupied by pixels with an elevation equal to 234 m is greater than the area occupy pixels with an elevation equal to 56 m, then 234 has a higher weight in the equation (proportional to it relative area).This query should do the work:
CREATE TABLE result01 AS
SELECT id,
sum(st_area(ST_Transform(the_geom, 32198)) * val) / sum(st_area(ST_Transform(the_geom, 32198))) as meanelev
FROM caribou_srtm_inter1
GROUP BY id
ORDER BY id;
Attachments (3)
- WKTRasterViewOf814buffers.gif (238.0 KB ) - added by 15 years ago.
- WKTRasterViewOfVectorizedTile.gif (115.9 KB ) - added by 15 years ago.
- WKTRasterViewOfIntersectionResult.gif (145.8 KB ) - added by 15 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip