#2502 closed task (fixed)
repo.osgeo.org snapshot management problems reported
| Reported by: | jive | Owned by: | robe |
|---|---|---|---|
| Priority: | major | Milestone: | Unplanned |
| Component: | SysAdmin | Keywords: | |
| Cc: |
Description
We are having a number of failed builds from individual developers and build automations (github actions, taavis0 making use of the osgeo snapshot repository.
So far these are hard to reproduce in isolation, so an experimental pull request has been setup here: https://github.com/geoserver/geoserver/pull/4461
As an example of a specific failure:
DEBUG] Could not find metadata org.geotools:gt-main:24-SNAPSHOT/maven-metadata.xml in local (/home/travis/.m2/repository)
Builds were also failing on gwc, but checking the build logs we can see these being uploaded:
Uploading to nexus: https://repo.osgeo.org/repository/geoserver-snapshots/org/geowebcache/gwc-web/1.18-SNAPSHOT/gwc-web-1.18-20200824.192934-1.jar
Checking the repo logs I have not yet seen these jars being removed:
2020-08-24 19:32:19,744+0000 INFO [quartz-7-thread-20] *SYSTEM org.sonatype.nexus.repository.maven.internal.orient.RemoveSnapshotsFacetImpl - Elapsed time: 1.840 s, deleted 0 components from 0 distinct GAVs
Attachments (1)
{kind=link}
Change History (17)
comment:1 by , 4 years ago
comment:2 by , 4 years ago
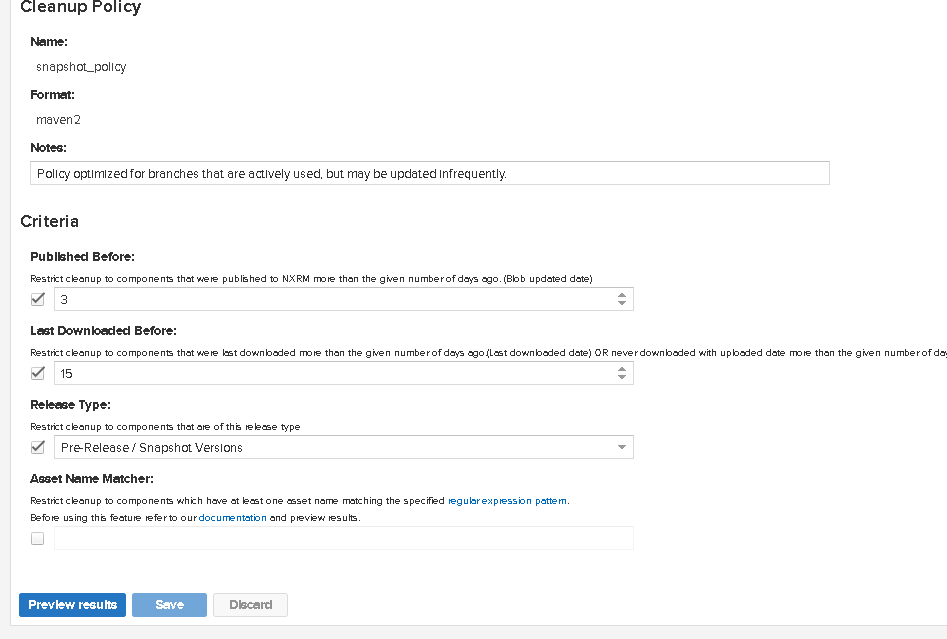
One thought -- could it be the cleanup policy jobs we have in place at fault here? Maybe we can disable them to see if things get better or increase longevity.
For example the cleanup policy I see has:

comment:3 by , 4 years ago
ignore my last comment. I see that was brought up on https://github.com/geoserver/geoserver/pull/4461#issuecomment-679257784
jive - so it sounds like you maybe have fixed this issue? Are you waiting to see if it is truly fixed before closing this or are there still outstanding problems?
comment:4 by , 4 years ago
I may of fixed the issue, some of the clean up tasks run daily so I wanted to give them a chance to work.
I left the "repair" tasks define and available to run manually if we ever have trouble with maven-metadata.xml files again.
comment:5 by , 4 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
follow-up: 9 comment:6 by , 4 years ago
jive in reviewing whether it's time to upgrade repo.osgeo.org, I came across this bug that affects 3.26.0, 3.25.1, 3.26.1 that is fixed in 3.27. It sounds an awful lot like what you were all experiencing.
https://issues.sonatype.org/browse/NEXUS-24988
Is it the same -- if so maybe I should upgrade our version to latest micro. We are currently running 3.25.1.
comment:7 by , 4 years ago
| Resolution: | fixed |
|---|---|
| Status: | closed → reopened |
This problem is persisting, and is getting quite frustrating with many downstream projects affected (for example unable to download gt-main-25-SNAPSHOT)
I presently cannot tell if the issue is:
a) either concurrent builds on build.geoserver.org both deploying to the same geotools repository.
b) or the nexus cleanup activities here producing a corrupt maven-metadata.xml files (which a manual run of a repair maven-metadata.xml activity fixes).
comment:8 by , 4 years ago
Q from Andrea:
Does repo.osgeo.org have any form of safety, like rate limiting and the like,that might trigger when the multiple builds we have all start in parallel and download jars from the repo?It could be in the repo manager, but also in whatever is fronting it on its way to the internet.
comment:9 by , 4 years ago
Replying to robe:
Is it the same -- if so maybe I should upgrade our version to latest micro. We are currently running 3.25.1.
Please let's try it!
comment:10 by , 4 years ago
Passing message on from Andrea:
"robe" comment two weeks ago seems to be spot on, an upgrade might be solving our issues?
comment:11 by , 4 years ago
| Owner: | changed from to |
|---|---|
| Priority: | normal → major |
| Status: | reopened → new |
robe I am increasing the priority (as this is effecting so many people) and passing the task to you with respect to upgrading nexus.
Thank you for hunting down NEXUS-24988 issue it really sounds like our problem.
comment:12 by , 4 years ago
I'll upgrade this later tonight and let you know once done. The upgrade generally takes about 5 minutes. Is it okay for me to go ahead later tonight or do I need to notify folks?
comment:13 by , 4 years ago
Please just update, I am looking forward to seeing this fixed. Thanks for much for finding it was a bug, and not just a mistake I made with setup.
comment:15 by , 4 years ago
| Resolution: | → fixed |
|---|---|
| Status: | new → closed |
Done with upgrade to 3.27.0-03. For future reference this is how I upgrade nexus.
Replace robe with your ldap account - sudoers are: robe,jive,tfr42
ssh robe@osgeo3-nexus sudo -i sh nexus.sh docker ps #confirm docker container has restarted
After that it does some internal upgrade stuff so repo.osgeo.org shows "Bad Gateway" Don't panic. I repeat DO NOT PANIC.
It takes about 5 minutes for the docker container to be fully functional. Don't panic, just be patient. In about 5 minutes after startup you should be able to go to
comment:16 by , 4 years ago
Great I will turn off my workarounds and we will see if the bug is fixed.
Important note, it's not the jar that goes missing, it's the maven-metadata.xml file that does. When working with snapshots, maven creates a timestamped directory and jars within, the maven-metadata.xml file tells clients how to go from "SNAPSHOT" to the actual pom and jar files. The maven-metadata.xml seems to be correctly uploaded, but after some time, it disappears. Without it, the clients don't know how to get to the jar and report it missing.
See more details here: https://github.com/geoserver/geoserver/pull/4461#issuecomment-679257784