| Version 12 (modified by , 13 years ago) ( diff ) |
|---|
Proposal title
| Date | 2012/03/22 |
| Contact(s) | Heikki Doeleman, Jose García |
| Last edited | |
| Status | Proposed for vote |
| Assigned to release | 2.7.0 |
| Resources | Available |
| Ticket # | #432 |
Overview
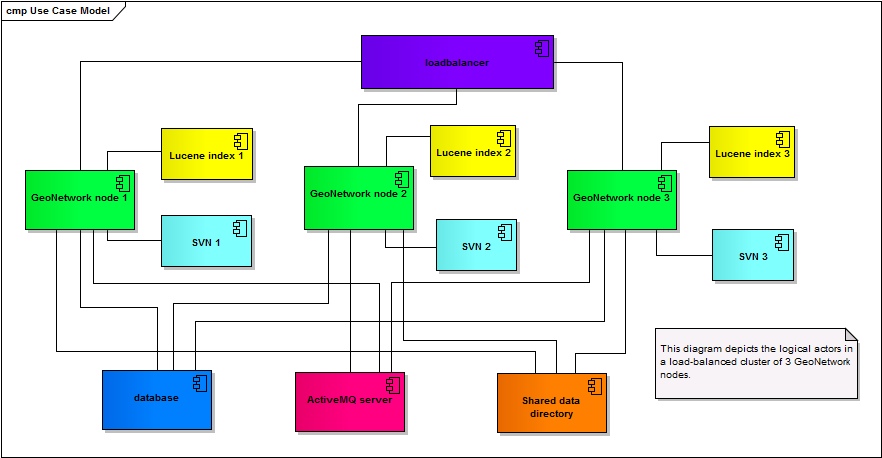
It is currently not possible to load-balance GeoNetwork, for various reasons described here. This proposal aims to make it possible to horizontally scale GeoNetwork by implementing the changes described below.
Proposal Type
- Module: ALL
Links
- Documents
Why you cannot scale GeoNetwork
- Email discussions:
- Other wiki discussions:
Voting History
Motivations
- Various users of GeoNetwork would like to be able to scale it horizontally to provide for increased performance and fail-over.
Proposal
This proposal assumes an infrastructure where multiple GeoNetwork nodes act as a single catalog. The nodes will share one database (this may be scaled separately but is not in scope of this proposal). Each node maintains its own local Lucene index and, if configured, SVN. This proposal does not address making GeoNetwork's HTTPSession serializable; therefore load-balancing using sticky sessions is presumed, and there is no support for transparent fail-over.
database primary key values
Currently, new records in the database receive primary key values that are generated in-memory, by the Jeeves class SerialFactory. To avoid clashes when multiple GeoNetwork nodes write to the same database, this should be changed. We propose to generate unique values by using random UUIDs for this. Another option would be using auto-increment column type, but that would make database replication all but impossible.
The generated UUIDs are slightly modified to replace their hyphens with underscores and to replace the first character, if it is a digit, with a letter character mapped to that digit. The reason for this is that the resulting values might be used as identifiers in languages like Javascript and are valid values for ID attributes in X(HT)ML.
Because there is no vendor-independent database column type for UUIDs, they will be stored in a column of type varchar2(36). Current databases will be migrated to use this type for their ID columns, without changing the current values (except for their type, obviously).
A notion exists that database perform faster if their (foreign) keys are auto-incremented integers, not strings. However if you google it, opinions whether this is really the case vary wildly and almost no-one offers actual measurements. Here is a post that does show measurements in MySQL which is re-assuring. Also, a change to String UUIDs allows for the removal of thousands of places in the GeoNetwork Java code where integers are converted to strings and vice-versa. Removing those increases performance because they're no longer done, and fewer short-lived objects are created which can help speed up garbage collection delays.
shared data directory
GeoNetwork creates directories for uploaded data that's associated with a metadata. The names of these (sub-)directories are calculated from the value of the metadata's database ID, probably to avoid having a totally flat structure with too many subdirectories. To support both new UUID-based and old integer-based IDs, the code doing this calculation will be modified so that it recognizes whether an ID is old or new; for old IDs, it uses the existing calculation method. For new IDs it generates a directory name that's /ab/cd/ef, using the first 6 characters of the ID. As UUIDs really are hexadecimal numbers, each (sub-)directory will have maximally 16*16 = 256 subdirectories, and the 3-level nesting creates room for in total 2563 = 16,777,216 metadata records with uploaded files. If you think it's not safe we could make it 4 levels, supporting 4,294,967,296 metadata.
In addition, each node has its own, local directories for Lucene, SVN and Cluster Configuraton (this last folder just contains a unique identifier of the node).
synchronization between nodes: JMS topics
In order to propagate changes made in one node to all others, JMS messages are placed on Topic/Subscribe channels. Each node is also using durable subscriptions to each topic. This decouples knowledge of the other nodes from each node and enables guaranteed delivery in correct order even after a node has been down.
Messages published to these topics are received by all nodes in the cluster. If a node is down, it will receive the messages published during its absence when it comes back up, in correct order. When all nodes have read the message, it will be removed from the topic (at some point).
The topics are:
- RE-INDEX Used to synchronize the nodes' Lucene indexes when metadata is added, deleted, updated, its privileges change, etc.
- OPTIMIZE-INDEX Used to propagate the Optimize Index command to all nodes.
- RELOAD-INDEX-CONF Used to propagate the Reload Index Configuration command to all nodes.
- SETTINGS Used to propagate a change in Settings to all nodes.
- ADD-THESAURUS
- DELETE-THESAURUS
- ADD-THESAURUS-ELEMENT
- UPDATE-THESAURUS-ELEMENT
- DELETE-THESAURUS-ELEMENT
- MD-VERSIONING Used to invoke the nodes' SVN versioning control.
- HARVESTER Used to propagate changes to Harvesters to all nodes.
- SYSTEM_CONFIGURATION Used to request all nodes to publish their System Information.
- SYSTEM_CONFIGURATION_RESPONSE Used to publish System Information.
synchronization between nodes: JMS queues
Messages published to these queues are received by one single node in the cluster. This can be any one of the nodes, whichever is first. When a node reads a message it is removed from the queue.
The queues are:
- HARVEST Used to run a Harvester. When clustering is enabled, a Harvester that's set to run periodically is invoked by periodic publication of a message to this queue; any one of the nodes in the cluster that picks it up first, will actually run the Harvester.
site uuid
The site uuid identifies this catalog. It's generated at start-up of a GeoNetwork node. We should prevent this happening more than once (e.g. if months later an extra node is added, it should not change). To achieve this, it will be inserted by the insert-data SQL scripts with a value of CHANGEME. When any node in the cluster starts up it checks the value and only if it is still CHANGEME, will it update its value to a UUID.
edit metadata lock
When a metadata is being edited by one user, and then another user also opens it for editing, the second user cannot save his changes because GeoNetwork maintains an in-memory 'version-number' to prevent this from happening. In a clustered scenario the in-memory version number is not globally available so this strategy must change.
The current implementation is in effect a form of pessimistic locking (concurrent edit sessions cannot successfully save), with additional disadvantage that the users are not informed when they start editing that they will lose their changes. This will be replaced by a more direct form of pessimistic locking, making it impossible to open a metadata for editing if it is being edited already at that moment. Admin functions will be available to force unlock metadata.
NOTE: this will not be implemented in the scope of this proposal; rather, we'll soon publish a separate proposal dedicated to improvements in locking, lifecycle and metadata state.
settings
Administrator users can enable clustering in the System Configuration. When enabled, a URL to the ActiveMQ JMS server needs to be specified.
documentation
See the GeoNetwork User Documentation for a description of how to install and configure a cluster.
Backwards Compatibility Issues
Any clients relying on the integer nature of database IDs, if they exist, need to change so they expect UUIDs instead.
New libraries added
ActiveMQ for JMS
Test cluster
We have a fully functional GeoNetwork cluster which uses 2 physical machines hosting 4 GeoNetwork nodes in 2 Tomcats and 1 Jetty. The nodes are not load-balanced to facilitate testing synchronization between nodes. You may access the test nodes at 1, 2, 3 and 4.
We do not guarantee anything about this test cluster and we'll take it down soon without notice.
Risks
Participants
Heikki Doeleman, Jose García
Attachments (2)
-
clustering.diff
(1.4 MB
) - added by 13 years ago.
Do not use patch with existing database; migration scripts yet to be included.
-
cluster.png
(15.1 KB
) - added by 12 years ago.
example cluster
{kind=link}
{kind=link}
Download all attachments as: .zip