
Opened 17 years ago
Closed 16 years ago
#2282 closed defect (fixed)
Performance of Scanning a Quadtree Index
| Reported by: | dmorissette | Owned by: | dmorissette |
|---|---|---|---|
| Priority: | normal | Milestone: | 5.2 release |
| Component: | MapServer C Library | Version: | 4.10 |
| Severity: | normal | Keywords: | |
| Cc: | sdlime, banders@…, jmckenna, project10 |
Description
Brock Anderson wrote to mapserver-users:
Hi List,
I ran into a curious situation with a quadtree (.qix) index on a shapefile. Basically the issue is that performance of scanning the index to fetch features is not as good as I expect. Some details:
I have a shapefile data set with 4 million polygons fairly normally distributed around British Columbia, Canada. I used 'shptree' to create a spatial index on that data. I have a very simple layer in my mapfile pointing at the data. Minimal styling, no labels, etc.
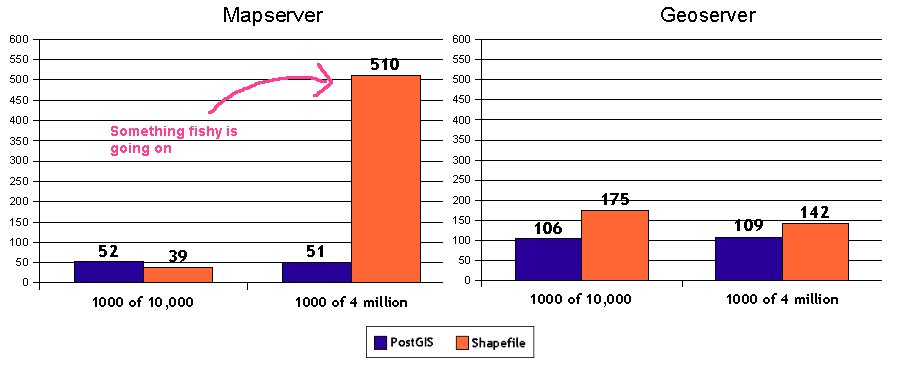
I then make a simple WMS request to fetch exactly 1000 features (limited by a bbox) from the layer. Mapserver take about 500ms. Seems a bit high. Geoserver can draw the exact same data, using the *same .qix* index in about 150ms. Naturally I made every effort to keep the comparison fair. No reprojection in either case, nearly identical styling, etc.
As a further comparison I noticed that Mapserver and Geoserver are nearly equal for fetching/drawing 1000 features from a smaller data set of just 10,000. Response time there is more like 120ms. So on large shapefile data sets Geoserver's index scanning seems to be substantially faster. Are there any map file options that might improve performance? Could it be that Geoserver simply has a faster implementation for traversing the quadtree?
I look forward to your thoughts.
Brock
Attachments (3)
{kind=link}
{kind=link}
Change History (14)
comment:1 by , 17 years ago
| Version: | 5.0 → 4.10 |
|---|
comment:2 by , 17 years ago
Here's the WMS request I was making. It draws 1000 features from the data set.
/cgi-bin/mapserv?map=/path/to/qix_test.map&service=wms&request=getmap&version=1.1.1&layers=polys_4M_10pt_shp&width=500&height=500&bbox=997974,997974,1002400,1003900&format=png&srs=epsg:3005
comment:3 by , 17 years ago
| Cc: | added |
|---|
comment:4 by , 16 years ago
| Cc: | added |
|---|
comment:5 by , 16 years ago
Mapserver stores the list of which shapes to draw as a bit map in shpfile->status, and iterates through this bitmap a number of times during the rendering cycle.
If the number of shapes is large (multi-millions) iterating through the bitmap multiple times can take a non-trivial amount of time.
Brock Anderson found that when drawing 1000 features out of a 3000000 record shape file, Geoserver completed in 30ms while Mapserver took 350ms.
Geoserver / Geotools store the features to be drawn as a list of feature ids, which means after their index scan, they have a list of 1000 entries to iterate through.
Mapserver stores the features to be drawn as flags in a bitmap, with as many entries as the underlying shapefile has records, and iterates through that (potentially very large) bitmap a few times.
In the case of an indexed shape file (which is what was tested) this is what happens.
- When opening up the shape file, mapserver reads the .shx file into memory, swapping (for little endian machines) the bytes of all the shape offsets and lengths, thereby calling SwapBytes 2*N times.
- For the indexed-and-index-is-useful case, msShapefileWhichShapes searches the tree (1) and then filters the search results (2)
- In maptree.c treeCollectShapeIds efficiently sets just the bits of the shapes that the tree finds within the search rectangle.
- The msFilterTreeSearch function checks every bitmap entry on the way to filtering out the entries that don't actually hit the search rectangle.
- Once the bitmap is populated, msShapeFileLayerNextShape function then iterates through every bitmap entry to see if that shape should be drawn.
So for a draw of 1000 (or 100 (or 10 (or 1))) features, in Brock's test Mapserver had to count to 3000000 four times, and load the whole SHX file off of disk (10s of Mb). In general, in a normal draw, SwapBytes will be called 2*N times and msGetBit will be called 2*N times.
In the unhappy event that you have set MAXFEATURES on your layer, to makes things faster, things actually get slower (in the large file case):
- First we check to see if the number of flags in the bitmap is greater than MAXFEATURES.
- Then we go back through and turn off all the ones we don't need.
A simple program on my 2.4Gh computer that runs the msGetBit function 3000000 times takes 30ms. So at a minimum, on a 3 million record file we do that four times, using 120ms of time just to run through the bitmap and prepare the SHX.
If we happen to have maxfeatures set, it gets 50% worse.
comment:6 by , 16 years ago
Thanks for the detailed comment Paul. That makes sense now. On the bright side the use of the bit array is limited to shapefiles so it should be reasonably easy to replace it with something more compact. What sort of a data structure would make the most sense? I choose the bit array way back because it was handy for dealing with duplicates as a shape index could be in multiple quadtree nodes.
Steve
comment:7 by , 16 years ago
This can be attacked in two halves: turning the SHX reading into a random access system; changing from a bitmap to a integer array.
I'm starting with the SHX change, because it seems easier to do in isolation, and will see what improvement comes of it.
Moving to the integer array makes sense, I think: collate array from tree, sort array, de-dupe array. Given that each map should pull no more than a few thousand things from each shape file, this should still be faster than the bitmap. It will become slower when rendering large proportions of large files, but that is hopefully not a common use case for sanely configured systems.
comment:8 by , 16 years ago
OK, I have attacked the SHX side, and gotten the results about 3x faster for the highly selective indexed case and about the same for the non-selective case when every feature has to be read and tested. I'll work on completing this patch before going forwards -- it needs to handle all the writing cases in mapshape.c (blurg).
by , 16 years ago
| Attachment: | shxperf.patch added |
|---|
Allow paged access to SHX files, instead of bulk load at start. Should leave standard performance intact, but inprove large file performance.
comment:9 by , 16 years ago
Summary: Performance patches radically improved the selective case and left the un-selective case in reasonable shape.
Definitions of tests:
- Indexed: Render 20 features of 1.8M, using an index scan to only pull the features needed from the SHP file. Tests the selective data access case.
- Unindexed: Render 20 features of 1.8M, using no index. Forces bounds from every feature to be read. Tests the un-selective data access case
- Mapserver 5.0
- Indexed: 164ms
- Unindexed: 990ms
- Mapserver SVN + SHX Patch
- Indexed: 48ms
- Unindexed: 1015ms
- Mapserver SVN + Bitmap Patch
- Indexed: 143ms
- Unindexed: 975ms
- Mapserver SVN + Bitmap Patch + SVN Patch
- Indexed: 28ms
- Unindexed: 991ms
Brock has sent me a copy of his test dataset (4 million shapes, approx 250MB). I haven't had time to test this yet.
Note that he was testing with Mapserver 4.10.2 on linux