
Table of Contents
Testing framework for GRASS GIS ¶
| Title: | Testing framework for GRASS GIS |
| Student: | Vaclav Petras, North Carolina State University, Open Source Geospatial Research and Education Laboratory |
| Organization: | OSGeo - Open Source Geospatial Foundation |
| Mentors: | Sören Gebbert, Helena Mitasova |
| GSoC link: | abstract |
| Source code: | trunk/lib/python/gunittest since revision 61225, sandbox/wenzeslaus/gunittest up to revision 61224 |
| Final source code: | trunk/lib/python/gunittest revision 61657 (documentation) |
| Documentation: | http://grass.osgeo.org/grass71/manuals/libpython/gunittest_testing.html |
Note that this page was for a GSoC project, for current state and development refer to documentation and follow grass-dev mailing list.
Here you can find information about various design decisions, unresolved issues, proposed ideas, and development during GSoC 2014.
Abstract ¶
GRASS GIS is one of the core projects in the OSGeo Foundation. GRASS provides wide range of geospatial analyses including raster and vector analyses and image processing. However, there is no system for regular testing of it's algorithms. To ensure software quality and reliability, a standardized way of testing needs to be introduced. This project will implement a testing framework which can be used for writing and running tests of GRASS GIS modules, C/C++ libraries and Python libraries.
Introduction ¶
GRASS GIS is one of the core projects in the OSGeo Foundation and is used by several other free and open source projects to perform geoprocessing tasks. The software quality and reliability is crucial. Thus, proper testing is needed. So far, the testing was done manually by both developers and users. This is questionable in terms of test coverage and frequency of the tests and moreover, it is inconvenient. This project will implement a testing framework which can be used for writing and running tests for GRASS GIS. This will be beneficial not only for the quality of GRASS GIS but also for everyday development of GRASS GIS because it will help to identify problems with the new code at the time when the change is done.
Background ¶
There was already several attempts to establish testing infrastructure for GRASS GIS, namely quality assessment and monitoring mailing list which is inactive for several years, then older test suite which was never integrated into GRASS GIS itself, and most recently a test suite proposal which was trying to interpret shell scripts as test cases. Also, an experience with usage of Python doctest at different circumstances shows that this solution is not applicable everywhere.
These previous experiences give us a clear idea what is not working (e.g. tests outside main source code), what is overcomplicated (e.g. reimplementing shell) and what is oversimplified (e.g. shell scripts without clear set up and tear down steps), and point us to the direction of an implementation which will be most efficient (general but simple enough), integrated in GRASS source code, and which will be accepted by the GRASS development team. The long preceding discussions also showed what is necessary to have in the testing framework and what should be left out.
The idea ¶
The purpose of this project is to develop a general mechanism which would be applicable for testing GRASS modules, libraries or workflows with different data sets. Tests will be part of GRASS main source code, cross-platform, and as easy to write and run as possible. The testing framework will enable the use of different testing data sets because different test cases might need special data. The testing framework will be implemented in Python and based on testing tools included in standard Python distribution (most notably unittest) which will not bring a new dependency but also it will avoid writing everything from scratch. The usage of Makefile system will be limited to triggering the test or tests with the right parameters for particular location in the source tree, everything else will be implemented in Python to ensure maximum re-usability, maintainability, and availability across platforms.
This project will focus on building infrastructure to test modules, C/C++ libraries (using ctypes interface), and Python libraries. It is expected that testing of Python GUI code will be limited to pure Python parts. The focus will be on the majority of GRASS modules and functionality while special cases such as rendering, creation of locations, external data sources and databases, and downloading of extensions from GRASS Addons will be left for future work. Moreover, this project will not cover tests of graphical user interface, server side automatic testing (e.g. commit hooks), using testing shell scripts or C/C++ programs, and testing of internal functions in C/C++ code (e.g. static functions in libraries and functions in modules). Creation of HTML, XML, or other rich outputs will not be completely solved but the implementation will consider the need for a presentation of test results. Finally, writing the tests for particular parts will not be part of this project, however several sample tests for different parts of code, especially modules, will be written to test the testing framework.
Project plan ¶
| date | proposed task |
| 2014-05-19 - 2014-05-23 (week 01) | Designing a basic template for the test case and interface of test suite class(es) |
| 2014-05-26 - 2014-05-30 (week 02) | Basic implementation |
| 2014-06-02 - 2014-06-06 (week 03) | Dealing with evaluation and comparison of textual and numerical outputs |
| 2014-06-09 - 2014-06-13 (week 04) | Dealing with evaluation and comparison of map outputs and other outputs |
| 2014-06-16 - 2014-06-20 (week 05) | Re-writing some existing tests using testing framework |
| 2014-06-23 - 2014-06-27 (week 06) | Testing of what was written so far and evaluating current design and implementation |
| June 23 | Mentors and students can begin submitting mid-term evaluations |
| June 27 | Mid-term evaluations deadline |
| 2014-06-30 - 2014-07-04 (week 07) | Integration with GRASS source code, documentation and build system |
| 2014-07-07 - 2014-07-11 (week 08) | Implementation of location switching |
| 2014-07-14 - 2014-07-18 (week 09) | Dealing with evaluation and comparison of so far unresolved outputs |
| 2014-07-21 - 2014-07-25 (week 10) | Implementing the basic test results reports |
| 2014-07-28 - 2014-08-01 (week 11) | Re-writing some other existing tests using testing framework |
| 2014-08-04 - 2014-08-08 (week 12) | Writing documentation of framework internals and guidelines how to write tests |
| 2014-08-11 - 2014-08-15 (week 13) | Polish the code and documentation |
| August 11 | Suggested 'pencils down' date. Take a week to scrub code, write tests, improve documentation, etc. |
| 2014-08-18 - 2014-08-22 (week 14) | Submit evaluation and code to Google |
| August 18 | Firm 'pencils down' date. Mentors, students and organization administrators can begin submitting final evaluations to Google. |
| August 22 | Final evaluation deadline |
| August 22 | Students can begin submitting required code samples to Google |
Design of testing API and implementation ¶
import unittest
import grass.pygrass.modules as gmodules
# alternatively, these can be private to module with setter and getter
# or it can be in a class
USE_VALGRIND = False
class GrassTestCase(unittest.TestCase):
"""Base class for GRASS test cases."""
def run_module(self, module):
"""Method to run the module. It will probably use some class or instance variables"""
# get command from pygrass module
command = module.make_cmd()
# run command using valgrind if desired and module is not python script
# see also valgrind notes at be end of this section
if is_not_python_script(command[0]) and USE_VALGRIND:
command = ['valgrind', '--tool=...', '--xml=...', '--xml-file=...'] + command
# run command
# store valgrind output (memcheck has XML output to a file)
# store module return code, stdout and stderr, how to distinguish from valgrind?
# return code, stdout and stderr could be returned in tuple
def assertRasterMap(self, actual, reference, msg=None):
# e.g. g.compare.md5 from addons
# uses msg if provided, generates its own if not,
# or both if self.longMessage is True (unittest.TestCase.longMessage)
# precision should be considered too (for FCELL and DCELL but perhaps also for CELL)
# the actual implementation will be in separate module, so it can be reused by doctests or elsewhere
# this is necessary considering the number and potential complexity of functions
# and it is better design anyway
if check sums not equal:
self.fail(...) # unittest.TestCase.fail
class SomeModuleTestCase(GrassTestCase):
"""Example of test case for a module."""
def test_flag_g(self):
"""Test to validate the output of r.info using flag "g"
"""
# Configure a r.info test
module = gmodules.Module("r.info", map="test", flags="g", run_=False)
self.run_module(module=module)
# it is not clear where to store stdout and stderr
self.assertStdout(actual=module.stdout, reference="r_info_g.ref")
def test_something_complicated(self):
"""Test something which has several outputs
"""
# Configure a r.info test
module = gmodules.Module("r.complex", rast="test", vect="test", flags="p", run_=False)
(ret, stdout, stderr) = self.run_module(module=module)
self.assertEqual(ret, 0, "Module should have suceed but return code is not 0")
self.assertStdout(actual=stdout, reference="r_complex_stdout.ref")
self.assertRasterMap(actual=module.rast, reference="r_complex_rast.ref")
self.assertVectorMap(actual=module.vect, reference="r_complex_vect.ref")
Compared to suggestion in ticket:2105#comment:4 it does not solve everything in test_module (run_module) function but it uses self.assert* similarly to unittest.TestCase which (syntactically) allows to check more then one thing.
Finding and running the test modules ¶
Test modules/scripts must have module/package character. This applies for both unittests and doctests, no exceptions. To have the possibility of import, all the GRASS Python libraries shouldn't do anything fancy at import time. For example, doctests currently don't work with grass.script unless you call a set of functions to deal with function _ (underscore) because of installing translate function as buildin _ function while _ function is used also in doctest. (This is fixed for GUI but still applies to Python libraries.)
Doctests (inside normal module code, in separate documentation, or doctests created just for the purpose of testing, see explanation of different doctest use cases) will be wrapped as unittest test cases (in the testsuite directory). There is a standard way to do it. Everything requires the possibility to import safely (without side effects).
unittest default implementation expects tests to not only by importable but really on path, so we would need to add the tested module on path beforehand in case we will use the classes as they are. In theory, it should be enough to add the directory containing file to the sys.path. This would add the advantage of invoking even separate test methods (testmodule.TestCase.test_method). It seems that simple sys.path.insert(0, '.') (if we are in directory with the test) and than import with name of the module works. On the other hand, the test discovery does much more tricks to get everything right, so it might be more robust than just adding directory to sys.path.
# file: gunittest/grass_main_test_runner.py from main import main sys.path.insert(0, '.') main() # simplified)
# run only one particular test method cd lib/python/temporal(/testsuite) python .../gunittest/grass_main_test_runner.py unittests_register.TestRegisterFunctions.test_absolute_time_strds_2
An alternative is to use test discovery even for cases when we know what we are looking for. The most easy way how to run tests in one file would be to use test discovery with a file name as pattern and file path as search directory (which limits the discovery just the one particular file). The disadvantage is that it is not possible to run individual test methods (as in the case of direct imports from path).
# invoke test module/script using test discovery but run only one module/script python .../gunittest/grass_main_test_runner.py discover -s lib/python/temporal/ -p unittests_register.py
GRASS modules which are Python scripts have one or more dots in the file name. This prevents them from being imported and so from being used in the tests directly. They itself can run themselves as tests but the testing framework is not able to run them using unittest's methods. Similarly, tests cannot load the functions from the file because this would require import. Doctest requires importable files too, so using it instead of unittest to test functions inside a script will not help.
Dealing with process termination ¶
There is no easy way how to test that (GRASS) fatal errors are invoked when appropriate. Even if the test method (test_*) itself would run in separate process (not only the whole script) the process will be ended without proper reporting of the test result (considering we want detailed test results). However, since this applies also to fatal errors invoked by unintentional failure and to fatal errors, it seems that it will be necessary to invoke the test methods (test_*) in a separate process to at least finish the other tests and not break the final report. This might be done by function decorator so that we don't invoke new process for each function but only for those who need it (the ones using things which use ctypes).
How the individual test methods are invoked ¶
This describes how unittest is doing it and we want to use as many classes (directly or by inheriting) from unittest as possible, so it will be probably also our system.
Loading of tests (pseudo code):
# finds all test methods of a given test case and creates test suite
# test suite class will get a list of instances of test case class, each with one method name (test method)
# testCaseNames contains test method names
def TestLoader.loadTestsFromTestCase(testCaseClass):
testCaseNames = filter(isTestMethod, dir(testCaseClass))
loaded_suite = self.suiteClass(map(testCaseClass, testCaseNames))
# finds all test cases in a module/script
def TestLoader.loadTestsFromModule(module):
for each object in module:
if isinstance(obj, type) and issubclass(obj, case.TestCase):
tests.append(self.loadTestsFromTestCase(obj))
suiteClass = suite.TestSuite
tests = self.suiteClass(tests)
# finds all tests (by direct import of what was specified or test discovery)
# passes found tests to test runner
def TestProgram.runTests():
self.test = self.testLoader.loadTestsFromModule(self.module)
self.result = testRunner.run(self.test)
# triggers the top level test suite
def TextTestRunner.run(test):
test(result)
Running of tests (pseudo code):
# invokes the separate tests
# does setup and teardown for class
# note that test suite can contain test suite or test case instances
def TestSuite.run(result):
for each test:
test(result)
# runs the test method and adds the information to the result
# does setup and teardown for an test case instance
def TestCase.run(result):
...
Analyzing module run using Valgrind or others ¶
Modules (or perhaps any tests) can run with valgrind (probably --tool=memcheck). This could be done on the level of testing classes but the better option is to integrate this functionality (optional running with valgrind) into PyGRASS, so it could be easily usable through it. Environmental variable (GRASS_PYGRASS_VALGRIND) or additional option valgrind_=True (similarly to overwrite) would invoke module with valgrind (works for both binaries and scripts). Additional options can be passed to valgrind using valgrind's environmental variable $VALGRIND_OPTS. Output would be saved in file to not interfere with module output.
We may want to use also some (runtime checking) tools other than valgrind, for example clang/LLVM sanitizers (as for example Python does) or profiling (these would be different for C/C++ and Python). However, it is unclear how to handle more than one tool as well as it is unclear how to store the results for any of these (including valgrind) because one test can have multiple module calls (or none), module calls can be indirect (function in Python lib which calls a module or module calling module) and there is no standard way in unittest to pass additional test details.
PyGRASS or specialized PyGRASS module runner (function) in testing framework can have function, global variable, or environmental variable which would specify which tool should run a module (if any) and what are the parameters (besides the possibility to set parameters by environmental variable defined by the tool). The should ideally be separated from the module output and go to a file in the test output directory (and it could be later linked from/included into the main report).
Having output from many modules can be confusing (e.g. we run r.info before actually running our module). It would be ideal if it would be possible to specify which modules called in the test should run with valgrind or other tool. API for this may, however, interfere with the API for global settings of running with these tools.
It is not clear if valgrind would be applied even for library tests. This would require to run the testing process with valgrind. But since it needs to run separately anyway, this can be done. In case we would like to run with valgrind test function (test_*), the testing framework would have to contain the valgrind running function anyway. The function would run the test function as subprocess (which is anyway necessary to deal with process termination). The advantage of integration into PyGRASS wouldn't be so big in this case. But even in the case of separate function for running subprocess, a PyGRASS Module class will be used to pass the parameters.
Other source code analyses ¶
Concerning static source code analysis, it seems that it is better to do it separately because it depends more on source code files or, in case of Python, modules and packages while tests seems to have their own structure. Also static source code analysis is not related to testing itself, although it is, for sure, part of quality assurance. However, it must be noted that some part of analysis can be one test case as suggested by pep8 documentation (test fails if code style requirements are not fulfilled). This could integrate pep8 with testing framework in an elegant way but it would require each testsuite to explicitly request this check.
For the static analysis of Python code, there is several tools commonly (i.e. in repositories of Linux distributions) available, most notably pep8, Pylint, and Flake8. Table of tools and their features (June 2014):
| tool | focus | HTML report | imports modules |
| pep8 | style (PEP8) | no | no |
| Pylint | errors and style | yes | no |
| PyChecker | errors | yes | |
| PyFlakes | errors | ||
| McCabe complexity checker | code cyclomatic complexity | ||
| Flake8 | combines PyFlakes, pep8, pep8-naming (if installed) and mccabe | yes | |
| pep257 | docstring style (PEP257) | no | |
| pep8-naming | naming conventions (PEP8) | ||
| dodgy | checking strange texts in source code (passwords, diffs) | no | no |
| frosted | PyFlakes fork | yes | |
| prospector | combines Pylint, PyFlakes, McCabe, pep8, pep8-naming, dodgy, frosted | no | yes |
The determining code coverage of the tests must be done during testing. Speaking about Python, some more advanced testing frameworks includes code coverage tools in them, namely coverage. Since unittest does not include coverage, GRASS will have to incorporate coverage into its testing framework. The basic usage is rather simple. If we consider that all is running in one Python process, we can just put the following (rather messy) code into some module which will be loaded before the tests will start (the main invoking script would be of course the best place):
import coverage
cov = coverage.coverage(omit="*testsuite*")
cov.start()
def endcov(cov):
cov.stop()
cov.html_report(directory='testcodecoverage')
import atexit
atexit.register(endcov, cov)
However, the HTML reports needs some polishing (especially the names of modules and paths) and moreover, the reports will be spitted by running different tests as separate processes. It it possible to link to these subreports and it might be even advantageous. But what is really an issue is running separate methods as separate processes, so the report is split in the way that it we have two (or more) reports, each of them reporting incomplete coverage but if merged together the coverage might be full. The merging seems like a challenge and would be probably hard on the level of HTML, so this would require using more low level API which is of course much harder. The default HTML report would be separate from the testing report, however this is not an issue and it might be even possible to add some links (with percentages) at proper places into the testing report.
Dependencies ¶
Dependencies on other tests ¶
The test runner needs to know if the dependencies are fulfilled, hence if the required modules and library tests were successful. So there must be a databases that keeps track of the test process. For example, if the raster library test fails, then all raster test will fail, such a case should be handled. The tests would need to specify the dependencies (there might be even more test dependencies then dependencies of the tested code).
Alternatively, we can ignore dependency issues. We can just let all the tests fail if dependency failed (without us checking that dependency) and this would be it. By tracking dependencies you just save time and you make the result more clear. Fail of one test in the library, or one test of a module does not mean that the test using it was using the broken feature, so it can be still successful (e.g. failed test vector library 3D capabilities and module accessing just 2D geometries). Also not all tests of dependent code have to use that dependency (e.g. particular interpolation method).
The simplest way to implement parallel dependency checking would be to have a file lock (e.g., Cross-platform API for flock-style file locking), so that only a single test runner has read and write access to the test status text file. Tests can run in parallel and have to wait until the file is unlocked. Consequently the test runner should not crash so that the file lock is always removed.
Anyway, dependency checking may be challenging if we allow parallel testing. Not allowing parallel testing makes the test status database really simple, it's a text file that will be parsed by the test runner for each test script execution and extended with a new entry at the end of the test run. Maybe at least the library test shouldn't be executed in parallel (something might be in the make system already).
Logs about the test state can be used to generate a simple test success/fail overview.
Dependencies of tested code ¶
Modules such as G7:r.in.lidar (depends on libLAS) or G7:v.buffer (depends on GEOS) are not build if the dependencies are not fulfilled. It might be good to have some special indication that the dependency is missing. Or, this might be also leaved as task of test author who can implement special test function which will just check the presence of the module. Thus, the fact that the tests failed (probably) because of missing dependency would be visible in the test report.
Dependencies of testing code ¶
The testing code could use some third party tools to compare results of GRASS to results of these tools. This of course might be very different set of dependencies than the GRASS itself code has. For example, we can compare result of some computation to result of a function available in SciPy. These test will probably be not allowed. If the tests would be allowed the most simple thing is probably check the dependencies in setUp or setUpClass methods. In case of import, it would need to be done once again in the actual test method (or we can assign the necessary imported classes to attributes).
# loading the dependency in setUp method and using it later
def setUp(self):
# will raise import error which will cause error in test (as opposed to test failure)
from scipy import something
# save this for later user in test method(s)
self.something = something
def test_some_test(self):
a = ...
b = self.something(params, ...)
self.assertEqual(a, b, "The a result differs from the result of the function from scipy")
Reports from testing ¶
Everything should go (primarily) to files and directories with some defined structure. Something would have to gather information from files and build some main pages and summary pages. The advantage of having everything in files is that it might be more robust and that it can easily run in parallel. However, gathering of information afterwards can be challenging. Files are really the only option how to integrate valgrind outputs.
There is TextTestRunner in unittest, the implementation will start from there. For now, the testing framework will focus on HTML output. However, the goal is something like GRASSTestRunner which could do multiple outputs simultaneously (in the future) namely HTML, XML (there might be some reusable XML schemes for testing results) and TXT (might be enriched by some reStructuredText or Markdown or really plain). Some (simple) text (summary) should go in to standard output in parallel to output to files. The problem with standard output is that functions and modules which we will use to prepare data or test results will be outputting to standard stdout and stderr and it would be a lot of work to catch and discard all this output.
It is not clear if the results should be organized by test functions (test_*) or only by test scripts (modules, test cases).
The structure of report will be based on the source code structure (something can be separate pages, something just page content):
libgisgmath- ... (other libraries)
rasterr.slope.aspect- ... (other modules)
vectorv.edit(testsuitedirectory is at this level)- test script/module
TestCaseclasstest_function/method- standard output
- error output
- ... (other details)
- test script/module
There will be (at least one) top level summary page with percentages and links to subsections.
It is not clear how to deal with libraries with subdirectories (such as lib/vector/vedit/) and groups of modules (such as raster/simwe/). Will each module have separate tests? Will the common library be tested (by programs/modules in case of C/C++, by standard tests in case of Python)? The rule of thumb would be to put all directories with testsuite directory on the same level. This is robust for any level of nesting and for directories having testsuite directory together with subdirectories having their own testsuite directories. In this system, a testsuite directory would be the only element and its attribute is the original directory in the code where it was discovered. Any higher level pages in report would have reconstruct the structure from these attributes. The advantage is that we can introduce different reconstructions with different simplifications, for example we can have lib (except for lib/python), lib/python, vector, etc. or we can have just everything on the same level, or just a selection (raster modules or everything useful for vectors from lib, lib/python and both raster and vector modules). However, this does not mean that files for the report cannot be stored in the directory tree which will be a copy of directory tree where the test were found. This is quite straightforward way to store the path where the testsuite directory is from. The script preparing the report can then find all testsuite (or testsuite-result or testresult) directories in this new directory tree and handle the test results as described above.
In the directory with the test result, there will be subdirectories for each test script/module with subdirectories for TestCase classes with subdirectories for their test_ functions/methods. This most nested directory will contain all test details. The passed/failed test result can be stored here but it will be stored for sure stored on the more upper levels.
We can introduce a rule that each test script/module can contain only one TestCase class which would simplify the tree. However, this is probably not needed because both the implementation and the representation can deal with this easily.
A page for testsuite will be the "central" page of the report. There will be list (table) of all test scripts/modules, their TestCase classes, and their test_ functions/methods with basic info and links to details. Considering amount of details there will be probably a separate page for each test_ function/method.
Details for one test (not all have to be implemented):
- standard output and standard error output of tests
- it might be hard to split if more than one module is called (same applies to functions)
- might be good to connect them since they are sometimes synchronized (e.g., in case of G7:g.list)
- Valgrind output or output by another tool used for running a modules in test
- might be from one or more modules
- the tested code
- code itself with e.g., Pygments or links to Doxygen documentation
- it might be unclear what code to actually include (you can see names of modules, function, you know in which directory test suite was)
- the testing code to see what exactly was tested and failed
- documentation of testing method and
TestCaseclass (extracted docstrings) - related commit/revision number or ticket number
- in theory, each commit or closed ticket should have a test which proves that it works
- this can be part of test method (
test_*) docstring and can be extracted by testing framework
- pictures generated from maps for tests which were not successful (might be applied also to other types but this all is really a bonus)
Generally, the additional data can be linked or included directly (e.g. with some folding in HTML). This needs to be investigated.
Each test (or whatever is generating output) will generate an output file which will be possible to include directly in the final HTML report (by link or by including it into some bigger file). Test runner which is not influenced by fatal errors and segmentation faults has to take care of the (HTML) file generation. The summary pages will be probably done by some reporter or finalizer script. The output of one standalone test script (which can be invoked by itself) will have (nice) usable output (this can or even should be reused in the main report).
Comparing results ¶
We must deal especially with GRASS specific files such as raster maps. We consider that comparison of simple things such as strings and individual numbers is already implemented by unittest.
Data types to be checked:
- raster map
- composite? reclassified map?
- color table included
- vector map
- 3D raster map
- color table
- SQL table
- file
Most of the outputs can be checked with different numerical precision.
We must have a simple guideline how to generate reference data. The output of G7:r.info for example is hardly comparable. It contains time stamps and user names that will differ for each test and platform. In addition the precision may be an issues between platforms for metadata values (min, max, coordinates). Hence the reference output must be parseable. One solution is, in case of metadata output (G7:r.info, G7:t.info, temporal modules in general), to require the output to be in shell format so that the reference check is able compare only these parts that contain values that will not change between test platforms. Alternatively we can use internal functions of doctest which are able compare texts where part of the text is ellipsis.
If we want to be able to test really all possible cases such as error outputs, it seems necessary to check that the error messages are saying what they should be saying, however this conflicts with the idea of testing under different locales (different locales would be still possible but the language would be always English). This might be solved by using regular expressions, doctest matching functions (with ellipses) or parsing just relevant part of the output.
Resources:
Naming conventions ¶
Methods with tests must start with test_ to be recognized by the unittest framework (with default setting but there is no reason to not keep this convention). This method is called test method.
The test methods testing one particular topic are in one test case (TestCase class child). From another point of view, one test case class contains all tests which requires the same setup and teardown.
Names of files with tests should not contain dots (except for the .py suffix) because the unittest.TestLoader.discover function requires that module names are importable (i.e. are valid Python identifiers). One file is a module in Python terminology, so we can say test module to denote a file with tests. However, we want these files to be executable, so this might lead also to the name test script.
A test suite is a group of test cases or more generally tests (test methods, test cases and other test suites in one or more files). A unittest's TestSuite class is defined similarly.
Name for directory with test is "testsuite". It also fits to how unittest is using this term (set of test cases and other test suites). "test" and "tests" is simpler and you can see it, for example in Python, but might be too general. "unittest" would confuse with the module unittest.
The preparation of the test is called setup or set up and the cleaning after the test is called teardown or tear down. There are setUp, setUpClass, tearDown and tearDownClass methods in TestCase class.
It is not clear how to call a custom script, class or function which will invoke the tests. Test runner would be appropriate but there is also TestRunner class in unittest package. Also, a report is a document or set of documents, however the class in unittest representing or creating the report is called TestResult.
The package with GRASS-specific testing functions and classes can be called gunittest (since it is based on unittest), gtestsuite (testsuite is reserved for the directory with tests), gtest, test, tests or grasstest. This package will be part of GRASS main package, so import will look like (using gtest):
from grass import gtest from grass.gtest import compare_rasters
Layout of directories and files ¶
Test scripts are located in a dedicated directory within module or library directories. All reference files or additionally needed data should be located there.
The same directory as tested would work well for one or two Python files but not for number of reference files. In case of C/C++ this would mean mixing Python and C/C++ files in one directory which is strange. One directory in root with separate tree is something which would not work either because tests are not close enough to actual code to be often run and extended when appropriate.
Invoking tests ¶
Test scripts will work when directly executed from command line and when executed from the make system. When tests will executed by make system they might be executed by a dedicated "test_runner" Python script to set up the environment. However, the environment can be set up also inside the test script and not setting the environment would be the default (or other way around since setting up a different environment would be safer).
To actually have separate processes is necessary in any case because only this makes testing framework robust enough to handle (GRASS) fatal error calls and segmentation faults.
Tests should be executable by itself (i.e. they should have main() function) to encourage running them often. This can be used by the framework itself rather then imports because it will simplify parallelization and outputs needs to go to files anyway (because of size) and we will collect everything from the files afterwards (so it does not matter if we will use process calls or imports).
Example run ¶
cd lib/python/temporal
Now there are two options to run the tests. First execution by hand in my current location:
cd testsuite
for test in `ls *.py` ; do
python ${test} >> /tmp/tgis_lib.txt 2>&1
done
The test output will be written to stdout and stderr (piped to a file in this case).
Second option is an execution by the make system (still in lib/python/temporal):
make tests
or
make test
which might be more standard solution.
Testing on MS Windows ¶
On Linux and all other unix-like systems we expect that the test will be done only when you also compile GRASS by yourself. This cannot be expected on MS Windows because of complexity of compilation and lack of MS Windows-based GRASS developers. Moreover, because of experience with different failures on different MS Windows computers (depending not only on system version but also system settings) we need to enable tests for as many users (computers) as possible. Thus, the goal is that we can get to the state where users will be able to test GRASS on MS Windows.
Basically, testing is Python, so it should run. We can use make system but also Python-based test discovery (our or unittest's). Invoking the test script on a MS Windows by hand and by make system may work too. Test will be executed in the source tree in the same way as on Linux. The problem might be a different layout of distribution directory and source code. Also some of the test will rely on special testing programs/modules which on Linux could be compiled on the fly while on MS Windows this could be a huge issue (see more below).
Libraries are tested through ctypes, modules as programs, and the rest is mostly Python, so this should work in any case. However, there are several library tests that are executable programs (usually GRASS modules), for example in gmath, gpde, raster3d. These modules will be executed by testing framework inside testing functions (test_*). These modules are not compiled by default and are not part of the distribution. They need to be compiled in order to run the test. We can compile additional modules and put them to one separate directory in distribution, or we can have debug distribution with testing framework and these modules, or we can create a similar system as we have for addons (on MS Windows) to distribute these binaries. The modules could be compiled a prepared on server for download and they would be downloaded by testing framework or upon user request. The more complex think could be standard modules with some special option (e.g., --test not managed by GRASS parser) which would be available only with some #define TEST and they would not be compiled like this by default.
Locations, mapsets and data ¶
The test scripts should not depend on specific mapsets for their run. In case of make system run, every test script will be executed in its own temporary mapset. Probably location will be copied for each test (testsuite) to keep the location clean and allow multiprocessing but this have very high cost so it should be only on some very high level. Cleanses of the location is hopefully not a big issue, i.e. it is expected to be clean. In case of running by hand directly without make, tests will be executed in the current location and mapset which will allow users to test with their own data and projections. It is not clear it it will be possible to parallelize in this case.
Tests (suites, cases, or scripts/modules) itself can define in which location or locations they should be executed as a global variable (both for unit and doctests, doctests in they their unittest wrapper, but probably doctests should always be NC sample location). The global variable will be ignored in case the test script is executed by hand or this will be possible to specify. When executed by make system, the test can be executed in all locations specified by the global variable, or one location specified by make system (or generally forced from the top). In other words, the global variable specifies what the test want to do, not what it is capable to do because we want it to run in any location.
We should have dedicated test locations with different projections and identical map names. It is not necessary or advantageous for tests to use the GRASS sample locations (NC, Spearfish) as test locations directly. We should have dedicated test locations with selected data. However, it seems that for maintenance reasons and doctest it is advantageous to use sample locations. For sure test locations can be derived from the sample locations or even can overlap with (let's say) NC but may contain less imagery but on the other hand, some additional strange data. The complication are doctests which are documentation, so as a consequence they should use the intersection of NC sample and testing location. The only difference between the locations would be the projection, so it really makes difference only for projected, latlon and perhaps XY.
All data should be in PERMANENT mapset. The reason is that on the fly generated temporary mapsets will have only access to the PERMANENT mapset by default. Access to other mapsets would have to be explicitly set. This might be the case when user wants to use his or her own mapset. On the other hand, it might be advantageous to have maps in different mapsets and just allow the access to all these mapsets. User would have to do the same and would have to keep the same mapset structure (which might not be so advantageous) which is just slightly more complex then keep the same map names (which user must do in any case). (e.g. aspect is 0-360) or checking the values with lower precision expecting the input data to be the same. Alternatively, tests themselves would have to handle different locations and moreover, this type of tests would always fail in the user provided location.
If multiple locations are allowed and we expect some maps being in the location such as elevation raster, it is not clear how to actually test the result such as aspect computed from elevation since the result (such as MD5 sum) will be different for each location/projection. This means that the checking/assert functions must be either location independent using general assumptions about data (e.g. aspect is 0-360) or checking the values with lower precision expecting the input data to be the same. Alternatively, tests themselves would have to handle different locations and moreover, this type of tests would always fail in the user provided location.
For running tests in parallel it might be advantageous to have temporal framework working in the mode with separate mapsets.
It is expected that any needed (geo-)data is located in the PERMANENT mapset when a specific location is requested. This applies for prepared locations. For running in the user location, it is not a requirement.
The created data will be deleted at the end of the test. The newly created mapset will be deleted (if it was created). If we would copy the whole location (advantageous e.g. for temporal things), the whole location will be deleted. The tests will be probably not required to delete all the created maps but they might be required to delete other files (or e.g., tables in database, temporal datasets) if they created some. The each tests might run in its own directory (and files should be created just with a name, not path), so it is clear at the end what to clear (or what to put to a report).
User should be able to disable the removal of created data to be able to inspect them. This would be particularly advantageous for running tests by hand in some user specified location. Some (or all) data can be also copied to (moved to, or created in) the report, so they would be accessible in a HTML report.
In case the mapset information is needed, then g.mapset -p (prints the current mapset) must be parsed within the test. An special case, a test of g.mapset -p itself will create a new mapset and then switch to the new one and test there.
Tests can provide also their own data and perhaps their own grassdata (GISDBASE) or location. This for sure does not save space but it would allow to have special data. For tests of mapset handling, re-projections and other management things, this is necessary. It is up to the test to correctly handle location switching (done only for subprocesses if possible) and clean up, although testing framework may provide some functions for this (e.g., to not do the clean up when not needed).
Testing framework can have a function to check/test the current location (currently accessible mapsets) whether it contains all the required maps (according to their name).
All reference files (and perhaps also additional data) will be located in the testsuite directory. There can be also one global directory with additional data (e.g. data to import) which will be shared between test suites and exposed by the testing framework. This must be specified separately or somehow connected to the location (we anyway need mapping of predefined location names to actual directories). It is not clear how to solve the problem of different projections. Projection limits the usage of data to one location except if you test (or want to risk) import to another location and re-projection.
The reference checking in case of different locations (projections) can only be solved in the test itself. The test author has to implement a conditioned reference check. Alternatively, a function (e.g., def pick_the_right_reference(general_reference_name, location_name)) could be implemented to help with getting the right reference file (or perhaps value) because some naming conventions for reference files will be introduced anyway. Easier alternative is to have different tests for different locations and separately the tests which are universal. The question is what is universal. Do we expect the universal tests not to be dependent on exact values, approximate values, or map names?
Testing framework design should allow us to make different decisions about how to solve data and locations questions.
Testing data will be available on server for download. The testing framework can download them if test is requested by user. The data can be saved in the user home directory and used next time. This may simplify things for users and also it will be clear for testing framework where to find testing data. The download can also download specialized data for individual tests (and perhaps even tests itself when they are not part of the distribution and C code on Unix and binaries on MS Windows).
GSoC weekly reports ¶
Week 01 ¶
- What did you get done this week?
I discussed the design and implementation with mentor during a week. The result of discussions is on project wiki page (this page, link to version). I will add more in the next days.
The code will be probably placed in GRASS sandbox repository (HTML browser), later it will be hopefully moved to GRASS trunk (HTML browser). However, the discussion about where to put GSoC source code is still open (gsoc preferred source location, at nabble).
- What do you plan on doing next week?
I plan to implement some basic prototype of (part of) testing framework to see how the suggested design would look like in practice and if it needs further refinement. So far it is how I have it in my schedule.
- Are you blocked on anything?
It is not clear to me how certain things in testing framework will work on MS Windows. I will discuss this later on the wiki page and grass-dev.
Week 02 ¶
- What did you get done this week?
The original plan for this week was to do a basic implementation of testing framework. However, I decided to start from the implementation available in Python unittest. This allowed me to continue in work on design implementation problems. I also studied the unittest implementation to understand what are the places which will be different in GRASS testing framework.
- What do you plan on doing next week?
The plan is to test unittest and doctest methods for evaluation and comparison of textual and numerical outputs (results) on GRASS use cases.
- Are you blocked on anything?
During next week, I (we) will need to make a decision if the tests will be limited to English language environment (or even English locales) because this can influence significant part of textual output comparisons.
Week 03 ¶
- What did you get done this week?
The plan was to test unittest and doctest methods for evaluation and comparison of textual and numerical outputs (results) on GRASS use cases. The simple cases are solved by unittest. Besides the code I put to sandbox I wrote some tests of some functionality related to g.list, g.mlist and g.mremove.
I discovered several functions in grass.script.core which can be used to solve more complex outputs of modules. So, I copied them, generalized them and wrote a tests for them (more work is needed). These functions can be used later to write tests but also in GRASS itself.
Regarding the issue with testing using different languages (translations). With the tests I wrote (especially the one for g.mremove), it seems that the best solution will be to use regular expressions or just Python in operator to test if the message contains the required information. In other words, test should be independent on language environment.
I also explored the the possibility of using code coverage to evaluate the tests. It seems that with Python coverage package, we can get code coverage (reports) for Python library without much burden at least for basic cases (no modules involved, no ctypes).
- What do you plan on doing next week?
The plan is to implement some way or ways of comparison of raster and vector maps. It would be good to implement comparison of other things too and to finish comparison of textual and numerical outputs from this week but the topic is so complex that I will focus just on raster maps first.
- Are you blocked on anything?
The fact that I also have to create the some tests to test the framework on some real world example slows me down but on the other hand, it is necessary and even very useful because I'm also testing things, such as the functions which will be used for creating the tests. And I discovered some problems right away.
Week 04 ¶
- What did you get done this week?
This week I was not able to work on GSoC as I planed because I needed to focus on other things, some of them GRASS-related. Most importantly, I was working on the GRASS FOSS4G workshop. Specifically, I was working on the format and technology to show examples and procedures in different languages (I'm not yet ready to publish the examples). In the relation to GSoC, I hope that the format I've designed will enable creation of tests based on materials like this which was one of my ideas for the alternative use cases for testing framework. By chance I also found a code quality evaluation tool, pep257, which is similar to pep8 but checks the style of docstrings.
- What do you plan on doing next week?
I will try to make advances in comparison of raster and vector maps. There are different alternatives how maps can be compared ranging from check sums of raster map's files to text-based comparison of exports of vector maps.
The plan for week five was rewriting some of the existing tests to the new format. But I already have some tests created in previous weeks and I'm writing tests for the framework itself, so I have enough material to work with.
- Are you blocked on anything?
My weekly plan got delayed but I hope to catch up the schedule in the next two weeks.
Week 05 ¶
- What did you get done this week?
I worked on the ticket #2326 since I realized that it is hard to test some things when the underlying functions or modules are not failing properly. With my mentor I discussed different ways of comparing map outputs. I was at a conference, so I was not able to actually implement any method. However, it seems that the already implemented textual comparisons and statistical values comparison (e.g., r.univar, r.info) might be more useful then the standard (MD5) check sums and value by value comparisons. I also started to write a documentation for testing because people started to ask about how to test.
- What do you plan on doing next week?
The plan for week six was testing of what was written so far but I'm testing as I go and it seems that it is actually too soon for evaluation of the current implementation which was also planed. Instead, I plan to implement raster and vector comparisons on different basis.
- Are you blocked on anything?
This is not real blocker, but I would need a large number of different tests which requires different map comparison methods to see which is the best one but since I cannot get the test without having the functions first I need to implement all of the methods, make them customizable and hope that other developers will decide later what is advantageous for their case.
Week 06 ¶
- What did you get done this week?
I've created a specialized functions to test output of modules such as r.info and r.univar against a reference set of values. This enables to test different properties of raster and vector maps and few other things (practically anything what is provided by some module as key-value pairs).
I also added the MD5 check sum comparison of files. The functionality of Luca's g.compare.md5 is not yet available but it should be easy to add it once needed (some merge with the module should be then considered).
The documentation is now updated, so although the framework is not integrated to GRASS yet, it is be now possible to write tests of GRASS modules which outputs raster and vector maps (tests of Python and ctypes function are in some limited way available from the beginning).
I again worked on the ticket #2326 because of its importance. By few experiments I discovered that there is a lot of hidden errors at least in GUI which are visible with more strict API. However, I'm not sure if it is possible to use this more strict API in version 7.x, so for now I used the ideas to create module calling functions in testing framework (currently called gunittest package).
- What do you plan on doing next week?
The plan is to start integration with GRASS and for the week after the plan is implementation of location switching for test. I think I will have to work on both these problems together.
- Are you blocked on anything?
Not really but it would be very helpful now to have tests of actual modules to see limitations of my current implementation.
documentation, gmodules Python module, report email
Week 07 ¶
- What did you get done this week?
After discussion with my mentor I introduced PyGRASS Module class as the main way to invoke modules in tests. The module is executed by an assert function, so the run and result can be examined throughly. I added functions and classes for finding and running tests in GRASS. The system is based on Python unittest package. Currently, several ways of invoking tests should be possible but it seems that only one or two will prevail in the future. The individual test files are executed as separate processes and there is a main process which controls everything. Most importantly it controls switching to the given gisdbase and location and it creates a mapset for each test file. The tests are loaded from a source tree starting in the current directory. All files in all testsuite directories are considered as tests and executed. Only portion of files can be selected by using a global variable in the file, i.e. only files which can run in the given location. The main process is now creating a HTML report which is not particularly fancy but it usable for examining results of larger number of tests.
I updated the documentation to reflect the recent improvements. Although the documentation is not finished yet, it can be used to write and run tests when gunittest package is added to PYTHONPATH.
I was thinking hard about the location handling and approach to different data and projections and I think that I have a solution which can work, although I don't say that it is simple. The description is in the documentation.
- What do you plan on doing next week?
I plan to put the gutittest package to trunk. The parts needed for writing tests are more stable then the parts for invoking and report generation, so I can consider putting only the stable ones to GRASS. I need to improve command line interface, maybe introduce make test and finally I would like to advance in location handling (which fits to the original plan for week 8).
Considering the state of report generation I can be more specific about plan for week 10. I will improve report generation for individual test files, add some paseable outputs, and add different summaries to the main report.
- Are you blocked on anything?
I need more tests to see how the ideas about location-specific and location-independent tests work in actual tests. I will of course use the existing tests but if you can contribute some more, please do.
Announcement: Testing framework now in trunk ¶
I moved testing framework (gunittest package) from sandbox to trunk in r61225.
You can run all tests from GRASS source code top directory using:
python -m grass.gunittest.main .../grassdata/ nc_spm_08 nc
You should be in GRASS session and in some testing location (it will not be
used but to be sure that nothing is damaged). First parameter is path to
GISDBASE, second is the name of location (you should use sample NC smp
location) and third parameter should be 'nc'. Running tests may take few
minutes and then open a file testreport/index.html with test results.
I'm working on documentation but assertion methods are well documented already and there is already a lot of examples in the source code. See directories named testsuite for example test files (ignore testsuite directory in root for now). Modules which have tests are t.rast.extract, r.gwflow, g.mlist, g.mremove, g.list, and r.slope.aspect.
You can write tests for raster modules pretty easily and in limited way it is possible to write tests for vector modules too. See the available assert methods (in gunittest and in unittest). When writing consider that you are in GRASS sample NC spm location.
Tests for modules such as r.info or r.univar are good starting point in
learning how to write tests and moreover, it would be advantageous to have
these core modules covered. If you would prefer rewriting rather then
writing, there is a lot of tests (or Pythod doctests) here and there which
might be integrated into the new framework. I can give you some pointers.
I'm getting feedback from Soeren but I would like to hear from other developers, too. So, let me know what you think.
Week 08 ¶
- What did you get done this week?
I extended the API for calling modules to allow convenient syntax, improved the naming of function and classes, added documentation, removed unnecessary code and introduced several other improvements based on the feedback of my mentor who is writing the tests for the code he maintains. I also added few more assert functions for evaluating the results. Additionally, I rewrote some existing tests to use the new testing framework and started to write test for r.slope.aspect module. Finally, I moved gunittest package from sandbox to trunk and changed the import paths and documentation accordingly.
The documentation is now available in dist.../docs/html/libpython/gunittest_testing.html after running make sphinxdoc.
The tests can be run for the whole GRASS using:
python -m grass.gunittest.main ...path/to/grassdata/ nc_smp_location_name nc # alternatively: python -m grass.gunittest.main nc_smp_location_name nc # general syntax: python -m grass.gunittest.main [gisdbasepath] location_name xx # no tests are using location identification now, so third parameter is ignored in fact
The command can be executed in any directory and it will find all tests in all subdirectories. The HTML report is stored in testreport/index.html. There is currently 17 successfully running tests files and 3 failing test files (each test file contains multiple tests). I did not advanced in testing of location switching. There is not enough tests in different locations. Anyway, main testing script switches to arbitrary location and executes each test file in unique mapset and working directory.
I postponed the integration with build system. The integration basically mean that make test would run the main test script in the current directory in some selected location. (Demolocation looks like a good choice in this case but this will limit us to tests which are not using any data.)
- What do you plan on doing next week?
The original plan for next week (week 9) is to implement missing comparison/assert methods. Currently, it is possible to compare kev-value pairs with different methods and precisions which covers most of the GRASS modules giving metadata and statistics about maps. Additional assert methods enables to compare raster maps in this way. For example, the function assertRastersNoDifference() can subtracts two raster maps and then checks their difference in a given precision. What is missing is comparison of vector and 3D raster maps and also temporal datasets.
- Are you blocked on anything?
I did not solved the issue of distribution of tests for different platforms. On Unix-like systems (+- Mac OS X), I suppose that all people wanting to test will be able to compile GRASS and download all locations they are interested in. There should be some rule in makefiles to build the C test modules, so that testing framework does not have to deal with that. However, doing this on MS Windows is not likely. Perhaps some special package with GRASS source code including testsuite directories, C test modules' binaries and locations would be the way to go.
src Testing on MS Windows section report email
Week 09 ¶
- What did you get done this week?
I added assert methods for testing vector equality based on v.info and difference of GRASS vector ASCII files, most notably assertVectorEqualsVector() and assertVectorEqualsAscii() methods. So, comparison of two vectors is now possible. I also added assert methods for 3D rasters but my tests for some of them are failing and also some refactoring will be needed in the future.
Additionally, I included two experimental methods for vector comparison based on buffering and overlays but I'm not sure if these are more useful than the ones based on ASCII and v.info. Perhaps these could be an inspiration for comparison of vectors for report if they are not equal.
There are no special methods to test temporal datasets but comparison of key-value outputs is applicable. By the way, there is currently 19 successfully running test files and 5 failing test files (each test file contains multiple tests). And thanks to the tests I also randomly found a bug revealed by more strict type checking (fix should be in r61272).
- What do you plan on doing next week?
The plan was to implement the basic test results reports. I've already done part of this, so now I will improve report generation for individual test files and add different summaries to the main report page (which summarizes all test files).
The structure or the report is the same as source code (where we look for the testsuite directories). The difference is that the testsuite directory is replaced by several directories, one for each test file. Each of these directories has its own index.html. The test case classes and methods probably will not have their own directories.
The index.html of one test file seems to be the central page of report containing basic information about individual tests (including descriptions) with links to more details such as stdout, stderr and some additional files (files created during the test). Information about tested modules will be gathered separately (using some test metadata or logging rather than using information about a directory).
The primary goal is, however, to add some parseable outputs such as key-value file with number of successful and failed tests. I'm considering also XML (XUnit XML test result format) which is understood by some applications or report tools (however, it seems that definition of this XML is not clear).
Perhaps writing some script which would gather information from different test runs would be beneficial.
- Are you blocked on anything?
I'm not really blocked but there is few things on testing framework todo list which I might not be able to solve in the next weeks.
First, the distribution is still not completely solved (see previous week discussion, Nabble link, Gmane link). Second, the system for different locations and data requirements still waits on being tested. Third, I postponed the integration with build system and improvements in command line interface.
Also some tests, including the one for comparison of 3D raster maps, are failing for me because of the following error (same as in #2074).
ERROR: Rast3d_get_double_region: error in Rast3d_get_tile_ptr.Region coordinates x 0 y 0 z 0 tile index 0 offset 0
To compile the latest documentation:
cd grass-source-code-root-dir make sphinxdoc # open file "dist.../docs/html/libpython/gunittest_testing.html"
To run all tests in all subdirectories in special location:
python -m grass.gunittest.main gisdbasepath nc_smp_location_name nc # open file "testreport/index.html"
To run one test file in the current location and mapset:
cd raster/r.gwflow/testsuite/ python validation_7x7_grid.py # see the output in terminal (stdout and stderr)
Week 10 ¶
- What did you get done this week?
I significantly improved the test file page which is the central page of the report in the sense that there you can get all the details. I also added details about successful and failed (individual) tests to main index page (the one with links to all test files). Additionally, I created different set of pages which sorts the test files from the point of view of testsuite directories which might be the primary way of browsing tests since it is aligned with how tests are included in the source code. The page for a given testsuite also contains approximate information about authors of tests and authors of tested code.
Each test file has now a key-value file which contains information about success, number of tests, and other information. These files can and are collected to obtain summaries. The key-value format was selected mainly because of its usage in GRASS GIS (otherwise, for example Python documentation for inputs and outputs recommends JSON).
I believe that I designed report classes in the way that they can be extended but already I can see some room for refactoring or at least for better organization. This might be a topic for week 13.
I did not created any XML output. The situation seems unclear and a lot of transformations are done to get XML working with different tools. On the other hand, with some tools even trivial XML with numbers (test statistics) should work and this should be easy to create from key-value files or directly. Also there is a unittest-xml-reporting package for Python unittest which should create XML in the style of Ant/JUnit. In theory this should work directly with gunittest. I was not considering database output much but I think that it is not needed now and it can be created from key-value files if necessary.
A also did not focus on CSS of the HTML reports. They are readable but that's all. Some CSS might be added in the future.
There is currently 20 successfully running test files and 5 failing test files, 9 successfully running testsuites and 4 failing testsuites, and 686 successfully running tests and 7 failing tests (533 of the tests are from PyGRASS module test).
I also added some tests for r.mapcalc rand() function and new behavior with seed in r61355.
- What do you plan on doing next week?
I plan to rewrite some of the existing tests using gunittest or write new ones. I already started to write something for r.slope.aspect and r.mapcalc.
If time allows, I would like to add some key-value summary files to reports and also introduce more options to report generation (currently, it cannot be configured).
- Are you blocked on anything?
I think that some CSS and JavaScript can improve the reports significantly but I did not included any nice design to HTML pages because it would cost me too much time (and it was not part of the GSoC plan anyway).
Index page for all test files ¶
Contains a table with one row for each test file. The testsuite directory is in the first column (precisely, it is a directory of testsuite directory of a test file). Table contains information about the failure/success of the file itself (i.e. return code) and also number of tests in each file. This page is generated during invocation of test files. The detail about tests are collected from key-value files which are also updated or created if they were not written by test file itself (e.g. because of segfault). Date and time when the test started and SVN revision number are included too. Some tests may not be included if the test file ends without writing this information (or if test file is not using gunittest).
")
Testsuite oriented pages ¶
Testsuite pages are compiled after all tests was completed based on the information stored in the key-value files. One main index page with links and statistics for a testsuite directories is created also a page for each testsuite directory is created. The main index page contains status of the whole directory, number of test files in it and number of tests in these files. The testsuite page contains a table with the same columns as the index page for all test files but only test files from testsuite directory are present. Additionally, this page contains information about authors of code and authors of tests which is obtained using SVN. The information is not precise because of limitations of what SVN can give and how the needed information can be extracted (more precise analyses could be done only using svn blame on each file and counting lines which would be very costly and still it would contain hight amount of uncertainty).
")
")
")
Successful test file ¶
Successful test file report page contains short summary and links to stdout and stdin. If the test case (TestCase class, or anything in test file) creates and registers some files with details about test (currently only HTML diff of two vector ASCII files), these are linked, too. If test file collected information about which modules were tested, summary table should contain this information (currently broken).
")
Failed test file ¶
Failed test file report page contains, in addition to what the successful page contains, also stderr (shortened if necessary). Stderr contains besides other things output from a clone of Python unittest test result runner and reporter classes, so here is the main information about what failed.
")
Week 11 ¶
- What did you get done this week?
The original plan was to rewrite some existing test but I decided that it will be more beneficial to work on reports to get them online and enable people to do the same. Particularly I improved report generation for test executed at different times and in different locations. As a proof of concept I created a cron job to run tests every day. Results are published at:
http://fatra.cnr.ncsu.edu/grassgistests/
The whole report structure is really general, so here are some links to more focused pages. Here is a page with overview of results for tests running in one location:
http://fatra.cnr.ncsu.edu/grassgistests/summary_report/nc/
Here is a page with list of all testsuites for a given location and date:
Here is a page for one testsuite for a given location and date. It contains lits of test files and overview about test and code authors.
Finally, here is an example of the most useful page. It is an result page for one test file containing general status, number of individual tests and error output if tests are failing. The error output contains information about individual tests.
When browsing the test results is it important to remember the system of tests described in documentation. Individual tests are methods of test case classes. One or more test case classes are in a test file which is a Python file executable as standalone script. Each directory in a source code can contain a directory named testsuite which can contain one or more Python files which are called test files. The automated testing scripts go through the source code and execute all test files in all testsuite directories.
I again did not focus on CSS of the HTML reports. Also the contents is just what is necessary, e.g. the summary tables might be on more pages.
There is currently 21 successfully running test files and 6 failing test files, 10 successfully running testsuites and 4 failing testsuites, and 751 successfully running tests and 46 failing tests (518 of the tests are from PyGRASS module test). This applies to a NC SPM location and the configuration of system at a computer where tests were executed.
When creating scripts for more complicated test executions, I improved the current system by better, more general API and better handing of some special situations. I also improved the key-value summaries with aggregated test results and introduced functions which shorten the file paths in outputs so that you don§t have to read through long useless paths (useless especially when result is published online).
I did not introduced any XML or JSON results since there is no immediate use for them (and they can be always generated from existing key-value files if we suppose the same amount of information). When creating the summary reports of another summaries I have seen how database storage would be useful because it would allows to do great queries at all levels of the report without the need to summarize over and over again manually. Even at the level of individual tests with hundreds of tests from different times wouldn't be a problem. SQLite seems as a good choice here except for the issues with parallelization and since parallelization (e.g. on the level of tests in different locations) is something what we want to do some other database (i.e. PostgreSQL) would be a better choice. Although I think that it would be pretty straightforward, I cannot make this within GSoC.
It should be also noted that I haven't tried any third party build/test/publish service. From what I have seen so far it seems that more steps would be needed for integrating into something like, for example a GitHub repository. Also (XML) format of tests might be a issue which I discussed last time. Finally, I was not able to find out what are the ways how large sets of testing data are handled. That's why I have decided to create less sophisticated but sufficient custom solution.
- What do you plan on doing next week?
The plan for week 12 is to work on documentation and I plan to do so.
Also I need to add some information to reports, most importantly the information about platform and configuration and also a descriptive names for test reports. This might be harder since these data might come from outside, so they have to be passed from the top to the very bottom and I should consider carefully what is really needed.
- Are you blocked on anything?
The online documentation for gunittest package is not generated although it compiles locally for me, so I'm not sure if everybody can compile it and access it now.
Blocker for the future improvements of reports might be actually a need for a database storage for test results which requires both test result and report classes able to write to database and HTML report generator classes to be able to read from database.
doc, broken gunittest package doc, example of cron job, example test result online
Week 12 ¶
- What did you get done this week?
This week's topic was documentation. Unfortunately, I was not able to work fully on GSoC as I expected. However, at the end I was able to get to the point when documentation is usable as is without further explanations (although is not as complete as I wanted it to be). Documentation now contains basic example, explanation of terminology and more advanced cases and detailed notes about selected details. Not all assert methods are fully documented but they should be understandable if nothing else, their source code and their tests should explain.
There is currently 22 successfully running test files and 5 failing test files, 11 successfully running testsuites and 3 failing testsuites, and 752 successfully running tests and 34 failing tests (507 of the tests are from PyGRASS module test). This applies to a NC SPM location and the configuration of system at a computer where tests were executed. Test are running once a day (so far 8 days; with one improvement during this period).
- What do you plan on doing next week?
Next week begin with suggested pencils down date, so I really plan only minor improvements, mostly in documentation. This time I know that I will not have much time for GSoC, so I don't plan much.
However, I will be able to provide support for those who decide to write some tests. Documentation is OK but hot line is better I guess. Note that test whether a module runs when right parameters are provided is good enough test and even this trivial test might prove helpful in the future.
- Are you blocked on anything?
I did not extended reports by including the information about platform, configuration and name. This should should be done for the reports before other things.
The online documentation for gunittest package is not fully generated and I don't know why, perhaps Python 2.6 versus 2.7 problem. It compiles locally for me, so I suggest other to do the same for now (make sphinxdoc).
Wiki: http://trac.osgeo.org/grass/wiki/GSoC/2014/TestingFrameworkForGRASS#Week12
Doc: http://grass.osgeo.org/grass71/manuals/libpython/gunittest_testing.html
Doc (current version rendered by Trac): http://trac.osgeo.org/grass/browser/grass/trunk/lib/python/docs/src/gunittest_testing.rst?rev=61572
Example of a cron job: http://grass.osgeo.org/grass71/manuals/libpython/gunittest_running_tests.html
Daily test results online: http://fatra.cnr.ncsu.edu/grassgistests/
Closing comment for ticket Missing guidelines for testing ¶
The ticket #2105 was asking for documentation but new possible tool for testing was discussed too, so here are the points from comment:7:ticket:2105 applied to current state of testing framework.
Python libraries Python:
gunittestunittestuse its assert methods throughgunittestdoctestuse only for documentation purposes and then test this documentation (i.e. do complex tests usinggunittest), there is a special way how to import tests
Functions in Python modules:
- doctest should at least partially work, currently best to invoke directly (without testing framework)
- to standardize/promote
--testparameter for GRASS modules might be useful here - others under investigation
Interface of C/C++ libraries:
- test using special (test) GRASS modules, invoke these separately for benchmark and as standard GRASS modules through
gunittest - test as Python libraries through ctypes
Internal (static, private, ...) functions in C/C++ libraries:
- not available (i.e., not possible to test directly/separately)
Functions in C/C++ modules:
- use special (test) GRASS modules as for C/C++ libraries
- to standardize/promote
--testparameter for GRASS modules might be useful here - static and private cannot be tested
C/C++ modules and Python modules:
gunittest
There are five other main areas of the testing topic:
- recursive running of tests
- e.g.,
python -m grass.gunittest.main --location nc_spm_grass7 --location-type nc make testnot implemented
- e.g.,
- reports/outputs
- textual output on stdout
- HTML
- parsable key-value files with summaries
- XML or database not implemented
- automatic and online running supported using custom scripts and documented for custom server
- tests currently runs every day
- no online testing services explicitly supported or tested
- supporting functionality especially that for comparing (maps, numbers) implemented or using
unittest - data for testing is a complex issue but most important are random data, data included in tests and NC SPM sample location, other can be used too but this was not much tested yet
Week 13 ¶
- What did you get done this week?
I've finally closed #2105 which partially stands behind this GSoC. I used my last comment there to evaluate what I've done in GSoC using the requirements which resulted from the ticket.
I've fixed report generation which was broken for the edge case when no test is executed because of error during set up phase.
There were two days without tests when report generation failed due to the fact that number of executed tests from one file was zero. This is fixed and the commit causing no tests to be executed (as well as the current number of failing tests) was reverted.
As I expected, I was not able to polish code or documentation but documentation is pretty much ready to use and the code is almost fully documented and has tests.
Finally, during writing this email, I decided to implement a new feature, shell scripts can be now used as test files.
Before using shell scripts, there was 11 successfully running test files and 18 failing test files, 4 successfully running testsuites and 12 failing testsuites, and 709 successfully running tests and 61 failing tests (510 of the tests are from PyGRASS module test).
- What do you plan on doing next week?
Next week no coding should be done for GSoC. Instead, the final evaluation should be submitted. I also plan to prepare code for submission to Google.
If time allows, I will also write down a TODO list or Final thoughts and create a new page for testing (and mark the GSoC one as read only).
- Are you blocked on anything?
Not for me, but for GRASS the blocker is still the lack of tests. There is a lot of shell scripts which can be used as test.
To make creating new tests from old ones simpler, I decided to add a possibility to use shell scripts in place of python scripts. in other words, a test file can by now .py or .sh. Shell script will be executed using sh -e -x. To implemented fast I had to drop some unused features and I made MS Windows compatibility worse but this can be fixed in the future and now we can have more tests which is more useful.
So, feel free to move shell scripts to testsuite directories (of things they are testing) and you can even create simple tests scripts from documentation.
However, note that writing a new tests using other things that gunittest is strongly discouraged because only by using gunittest we are able to obtain detailed test results and (optionally) extent testing by analyses such as valgrind.
Note also that alternative to allowing shell scripts directly is calling a shell script from a Python test file. The only condition is that shell script must be in data directory of the testsuite and Python file must return a return non-zero if tests failed (e.g. using set -e).
daily test results online, ticket #2105, shell scripts becoming tests: r61653, r61658, r61660, report email
Final report ¶
It was not required by GSoC but I wanted to do some final report to summarize what was done and what could be done in the future. So, here it is.
Ways to run tests:
- each file separately in the current location and mapset you are in
- good for testing the code you are just writing
- good for writing the test
- running all tests in subdirectories (all test files in all testsuite directories)
- generates a report
- runs in GRASS session but does not touch the current mapset
- switches to specified location and mapset
- generates detailed report
- using higher level script to run tests from outside GRASS session
Ways to write tests:
- using GRASS Python package
gunittest- works in the same way as
unittestbut adds GRASS-specific functionality - good tools for test author
- allows generation of HTML reports
- enables fine control over execution of GRASS modules in the future
- this is the preferred way, other ways are discouraged
- works in the same way as
- using standard Python
unittest- only general testing functionality available
- rich report will not be generated
- no particular reasons for using this
- any Python script
- Python syntax is used which is better then Shell
- no special reports or functions are provided
- not recommended
- Shell scripts
- provided to accommodate existing tests
- better Shell test then no test
- probably won't run on MS Windows
- not recommended
When writing tests, gunittest package allows in a convenient way to:
- compare map statistics or info to a given reference
- compare raster and 3D raster maps with each other
- compare vector maps using different ways
- compare numbers and texts
Generated test reports contain:
- key-value file with results for each test file
- HTML report with:
- detailed page with important information for each test file
- summary pages for each
testsuitedirectory - summary pages for all tests according to test files,
testsuitedirectories, ...
Things which should be solved in the short term:
- tests should specify the location they can run in
- some code already exists for this but parsing of LOCATION variable or tag needs to added
- the missing piece is determination of which location types we need (e.g., same maps but different projections)
- encapsulate removal of maps and other files
- test tests on more platforms
- Mac OS X should just work
- MS Windows might be challenging at the beginning but everything is in Python, so at least basics should work
- Python 2.6 compatibility
- there is
unittest2for backwards compatibility but it seems not trivial
- there is
Long-term plans:
- integrate
valgrind, and other tools such as profiling tools - provide coverage for Python code, C modules and library
- introduce static test of source code (probably separately) such as
pylint,cppcheckor custom regular expression - time execution of modules
Smaller or bigger things which can be done but are not necessary:
- parallelization (can be done at different levels, higher levels are easier and might give better speedup)
- store test results in a database
- store test results in a standardized XML for better integration with other systems
- use UTC times everywhere
- add more information about system and environment to test reports
- create latest test results page in report
- create per-module result page in report with list of not tested modules
- link the tested code in reports
- output maps and their differences as images to report
- make removal or maps and other files optional
- standardize precision handling, now every test needs to decide individually (relative, absolute, float, integer)
- create better interface for running individual tests, all tests and make with appropriate defaults
- create interface for test filtering or running list of tests
- create method for running part of the tests and integrating results into a bigger report (to test just the part of the source code which has changed)
- check for invalid tests: test files without "main" or test methods without assert function calls
- use some JavaScript interactive graphs for the overviews
- create a image with test results which can be included to other websites
- support report with different system configurations (e.g. compiler)
- provide functionality for benchmarks (benchmarks and tests should be something different but the needed functionality might be very similar and also tests can be timed and profiled and benchmarks will show if something is broken, however benchmarks might take much longer time to run)
- run tests with and without debugging messages and without (both are useful since debug can be too verbose), setting the right variables before the tests, similar things apply to verbose modes and compilation in debug mode and without
- provide information about segmentation fault (that it was SIGSEGV, traceback, ...) and similar cases
- monitor subprocesses which should end with the parent but they don't (applies especially to processes which are running independently on calling process)
It would be also interesting to compare this testing framework to the older "test suite", for example which features are missing.
It is probably good to mention that documentation with examples is in Python API Sphinx documentation. You can get it by make sphinxdoc. Also there is a lot of tests already written, so you can get inspiration there (search for testsuite directories) but read the documentation too, to understand basic concepts.
And there is probably no need to mention that although there is a lot of tests which can serve you as examples there is not enough tests to cover all GRASS functionality, so please contribute. Start with the modules, you are using. You can also contribute by running the tests on your platform and specific system configuration. I'm running the tests once a day and the HTML report is available online.
Thanks to the test, we have already discovered several bugs soon after they were introduced (the day of after the commit). Additionally, some older bugs were discovered by thorough testing. This is very encouraging to me and I hope also to others.
Attachments (6)
-
test_files_index.png
(43.5 KB
) - added by 11 years ago.
test files index page in report (week 10)
-
testsuites_index.png
(79.8 KB
) - added by 11 years ago.
testsuites index page in report (week 10)
-
testsuite_gmlist.png
(35.3 KB
) - added by 11 years ago.
g.mlist testsuite page in report (week 10)
-
testsuite_gunittest.png
(55.7 KB
) - added by 11 years ago.
gunittest testsuite page in report (week 10)
-
test_file_trastextract.png
(36.4 KB
) - added by 11 years ago.
one t.rast.extract test file report page (week 10)
-
test_file_r3assert.png
(157.7 KB
) - added by 11 years ago.
gunittest 3D raster asseritations test file report page (week 10)
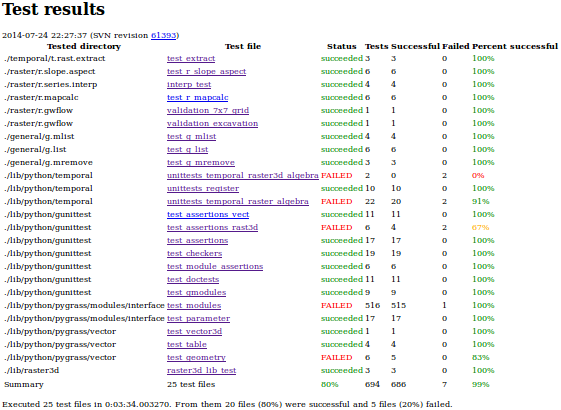{kind=link}
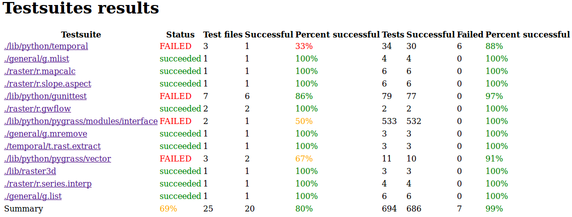{kind=link}
{kind=link}
{kind=link}
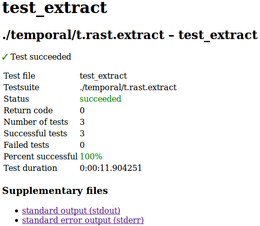{kind=link}
{kind=link}
Download all attachments as: .zip