#6422 closed defect (fixed)
Incorrect color interpolation in gdaldem (color-relief mode)
| Reported by: | dsogari | Owned by: | warmerdam |
|---|---|---|---|
| Priority: | normal | Milestone: | 2.1.0 |
| Component: | default | Version: | 2.0.2 |
| Severity: | normal | Keywords: | gdaldem color-relief |
| Cc: |
Description
Hello, I have some points to discuss with you about the behaviour of gdaldem in color-relief mode.
Firstly, in apps/gdaldem.cpp:851, inside function GDALColorReliefGetRGBA, there's an algorithm to "Find the index of the first element in the LUT input array that is not smaller than the dfVal value" (quoted from the source file). It uses comparison operator '<', but I believe it should be using '<='. A diff file is attached to show where the comparison operators should be replaced.
Otherwise, it can lead to "holes" in the output raster if the color palette file has repeated entries with the same value and the input raster has pixels that match that value exactly. An example of such raster is attached and the palette file used for testing can be found here: http://soliton.vm.bytemark.co.uk/pub/cpt-city/arendal/temperature.cpt
Secondly, I think you should consider replacing qsort (called in line 1180) by a stable sorting algorithm, or devise a way to handle equivalent color entries. This is because of the nature of qsort, which might reverse the original order of equivalent color entries.
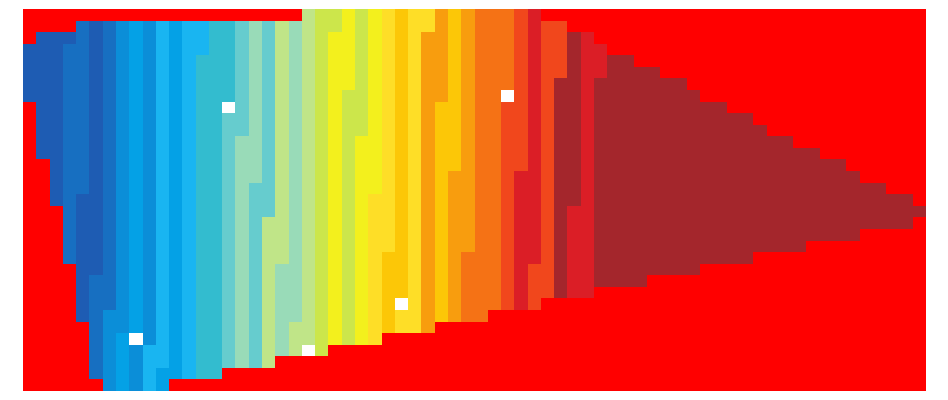
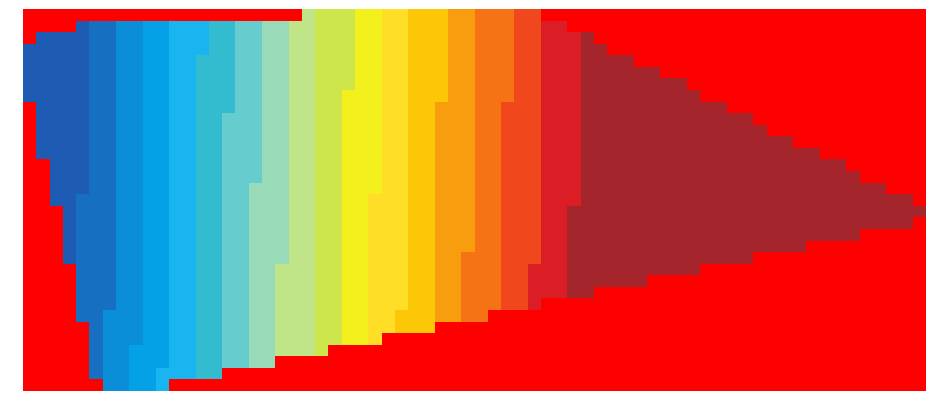
In the case of the aforementioned palette file, the resulting raster can be seen in the attached file named "gdaldem_before.png". Its appearance isn't quite good, as the input pixel values increase monotonically from left to right, while the output colors change back and forth.
In my environment I was able to use the std::stable_sort function provided by <algorithm>. The resulting raster can be seen in the attached file named "gdaldem_after.png", whose appearance is much better.
Lastly, the value of nodata is being used together with the other values during interpolation. For instance, in nearest interpolation if a pixel value lies closest to the nodata value, it will be assigned the same color as nodata pixels. Is this behaviour intended?
Thank you
Attachments (6)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (13)
by , 8 years ago
| Attachment: | gdal-2.0.2.patch added |
|---|
comment:1 by , 8 years ago
With such a palette, when pixel values hit one repeated entry, it is not determinate which entry should be picked up. We can decide one (the first or the last), but that should be written as a comment.
Your patch is probably a first step to fix that, but in the later lines of the function, I'm wondering if some changes shouldn't be done as there seems to be assumptions that entries are strictly growing. Particularly the following lines :
if (eColorSelectionMode == COLOR_SELECTION_EXACT_ENTRY &&
pasColorAssociation[i-1].dfVal != dfVal)
if (eColorSelectionMode == COLOR_SELECTION_NEAREST_ENTRY &&
pasColorAssociation[i-1].dfVal != dfVal)
double dfRatio = (dfVal - pasColorAssociation[i-1].dfVal) /
(pasColorAssociation[i].dfVal - pasColorAssociation[i-1].dfVal);
This really depends if the 'i' picked up is the first one or the last one (wondering also how that would work for more than 2 repetitions...)
From a quick check, std::stable_sort could be safely used as it is available in C++98.
Regarding selection of the nodata entry in nearest interpolation, yes, that's probably not what would be wished. And presumably linear interpolation with the nodata entry shouldn't be done at all.
Generally all those issues can be fixed by altering the color palette to add new entries (one just above or below the nodata value, with a RGB that is identical to the closest valid RGB) or modify existing ones (add a small epsilon to the duplicated entries)
comment:2 by , 8 years ago
Thanks Rouault. You're right, we could decide which entry to pick up every time the pixel value hits the entry. Or else ignore repeated entries while parsing the palette file.
Your concern about the later lines in the function could propably be addressed with this, to avoid getting NaN in the calculation of dfRatio in case the 'i' picked up is not the first one:
if (pasColorAssociation[i-1].dfVal == dfVal)
{
*pnR = pasColorAssociation[i-1].nR;
*pnG = pasColorAssociation[i-1].nG;
*pnB = pasColorAssociation[i-1].nB;
*pnA = pasColorAssociation[i-1].nA;
return TRUE;
}
But I guess that altering the color entries after reading the palette file is a smart choice. This avoids breaking the current algorithm assumptions. For instance, in pseudo-code:
sort(entries)
previous = null
added = false
for (entry in entries)
{
// NaN comparison is always false, so it handles itself
if (srcHasNoData && entry.value == srcNoDataValue)
{
if (previous)
{
// add one just below the nodata value
add (entry.value - epsilon, previous.color) to entries
added = true
}
}
else if (srcHasNoData && previous && previous.value == srcNoDataValue)
{
// add one just above the nodata value
add (previous.value + epsilon, entry.color) to entries
added = true
}
else if (previous && entry.value == previous.value)
{
// modify repeated entry
previous.value -= epsilon
}
previous = entry
}
if (added)
sort(entries)
I'm not sure this is correct though.
comment:3 by , 8 years ago
Your code and pseudo-code look plausible. Want to create a patch for that ? Against trunk would be ideal. And a test case in autotest/utilities/test_gdaldem.py would be welcome too.
comment:4 by , 8 years ago
Sure! I got it. Only, I don't know how to go about the test case. But I'll create the patch for gdaldem.cpp and post it here.
comment:5 by , 8 years ago
This is what I could do. In my environment the tests were ok. However, it should be reviewed thoroughly.
comment:6 by , 8 years ago
| Milestone: | → 2.1.0 |
|---|---|
| Resolution: | → fixed |
| Status: | new → closed |
diff file for gdaldem.cpp