Opened 13 years ago
#588 new enhancement
Index / Add metadata related resources content analysis for full text search
| Reported by: | fxp | Owned by: | |
|---|---|---|---|
| Priority: | major | Milestone: | Future release |
| Component: | General | Version: | |
| Keywords: | Cc: |
Description
The idea is to analyse related resource defined in the metadata record in order to improve search results. For example, if a WFS layer is linked to a metadata record, then the GetFeature response could be analyzed and index and user could search using feature attributes like names, ... Another interesting case is when you link the documentation of a layer in the metadata, the content of the documentation is also indexed.
Add a service to:
- analyze a metadata record for related resources (eg. PDF, WFS GetFeature, OpenOffice, webpage)
- parse the related resources
- add content to the full text search field (ie. any)
Metadata analysis phase is based on an XSLT. Main idea is to grab gmd:URL elements. The analysis doesn't need to define the content type which is usually automatically detected by the AutoDetectParser.
Document parser is based on Apache Tika project: http://tika.apache.org/. It supports different formats (http://tika.apache.org/0.9/formats.html) and could be used for XML based content like KML, WFS GetFeature response for example.
As a first approach, the service is run manually:
- to analyze the record and return a report on related ressources
- metadata.index.extra?uuid=894ab2ff-e16c-477c-be7a-009f5da8289b
<response> <resources> <file type="xml" url="http://services.sandre.eaufrance.fr/geo/ouvrage?service=WFS&version=1.0.0&REQUEST=DescribeFeatureType&TYPENAME=REPOM"/> <file type="xml" url="http://services.sandre.eaufrance.fr/geo/ouvrage?service=WFS&version=1.0.0&REQUEST=GetFeature&TYPENAME=REPOM"/> <file type="pdf" url="/home/work/documentation/gis/data/env/landcover.pdf"/> <file type="unknown" url="http://www.eea.europa.eu/publications/COR0-landcover/at_download/file"/> </resources> </response>
- metadata.index.extra?uuid=894ab2ff-e16c-477c-be7a-009f5da8289b
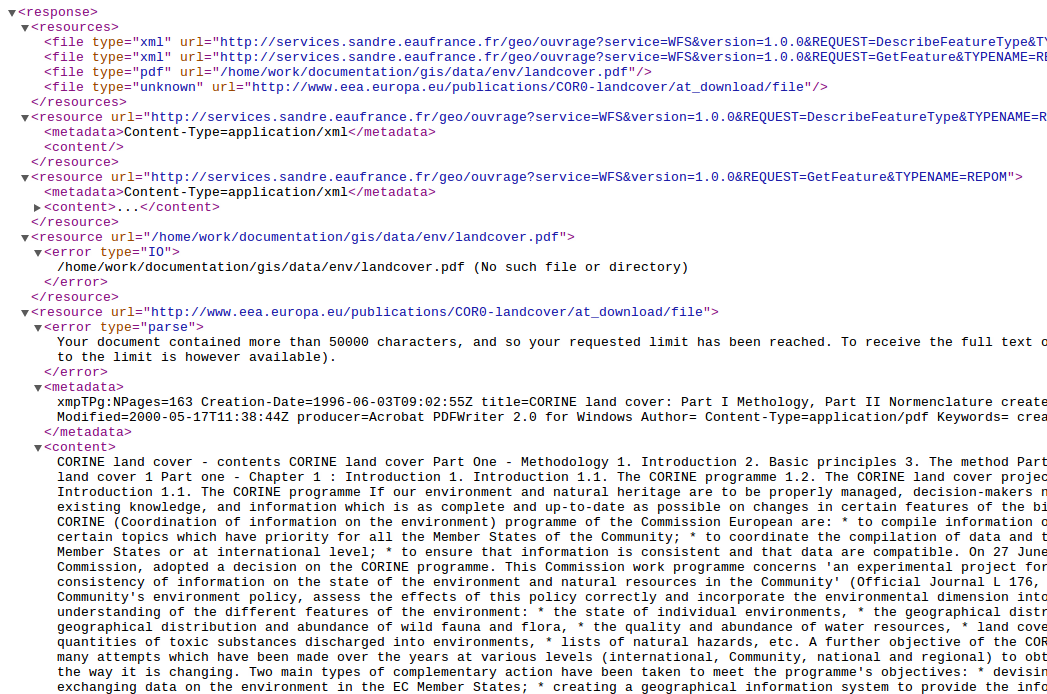
- to analyze and parse the related resources returning the extracted metadata and content (see screenshot)
- metadata.index.extra?uuid=894ab2ff-e16c-477c-be7a-009f5da8289b&parse=true
- to analyze, parse and re-index the document with the extracted content added to the full text search field.
- metadata.index.extra?uuid=894ab2ff-e16c-477c-be7a-009f5da8289b&parse=true&index=true
Note:
- An update of the record will remove the extracted content. The analysis needs to be runned again.
- Document parsing could take more or less time to download and/or parse according to its location and size.
- Index size will increase
- Users may not understand why a metadata is found because the search criteria comes from the related resources and not the metadata document itself.
Improvements:
- Add a GUI
- Add a flag to the metadata where the editor could define if extra content should be added when the record is indexed ?
- Add a background task to do this automatically on all records ?
References:
- Old discussion about KML and WFS indexing http://osgeo-org.1803224.n2.nabble.com/Related-document-indexing-eg-kml-and-wfs-indexing-tt3708088.html
{kind=link}
{kind=link}